Загрузка исходных данных с помощью Django 1.7 и миграция данных
Недавно я переключился с Django 1.6 на 1.7, и начал использовать миграции (я никогда не использовал Юг).
До 1.7 я загружал исходные данные в файл fixture/initial_data.json, который был загружен командой python manage.py syncdb (при создании базы данных).
Теперь я начал использовать миграции, и это поведение устарело:
Если приложение использует миграции, автоматическая загрузка светильников не производится. Поскольку для приложений в Django 2.0 потребуется миграция, это поведение считается устаревшим. Если вы хотите загрузить исходные данные для приложения, подумайте об этом в процессе переноса данных. (https://docs.djangoproject.com/en/1.7/howto/initial-data/#automatically-loading-initial-data-fixtures)
Официальная документация не содержит четкого примера того, как это сделать, поэтому мой вопрос:
Каков наилучший способ импорта таких исходных данных с помощью переноса данных:
- Записать код Python с несколькими вызовами
mymodel.create(...), - Используйте или пишите функцию Django (как вызов
loaddata) для загрузки данных из файла привязки JSON.
Я предпочитаю второй вариант.
Я не хочу использовать Юг, поскольку Django, похоже, теперь может сделать это изначально.
-
3Кроме того, я хочу добавить еще один вопрос к первоначальному вопросу OP: как мы должны выполнять миграцию данных для данных, не принадлежащих нашим приложениям. Например, если кто-то использует каркас сайтов, ему нужно иметь данные с данными сайтов. Поскольку структура сайтов не связана с нашими приложениями, куда мы должны поместить эту миграцию данных? Спасибо !Serafeim
-
0Важным моментом, который здесь еще никто не рассмотрел, является то, что происходит, когда вам нужно добавить данные, определенные при переносе данных, в базу данных, на которой вы имитировали переносы. Поскольку миграции были фальшивыми, миграция данных не будет выполняться, и вы должны сделать это вручную. На этом этапе вы можете просто вызвать loaddata для файла фикстуры.hekevintran
8 ответов
Обновление: см. Ниже комментарий @GwynBleidD о проблемах, которые может вызвать это решение, и см. Ответ @Rockallite ниже, чтобы узнать о подходе, более устойчивом к будущим изменениям модели.
Предполагая, что у вас есть файл <yourapp>/fixtures/initial_data.json в <yourapp>/fixtures/initial_data.json
-
Создайте пустую миграцию:
В Джанго 1.7:
python manage.py makemigrations --empty <yourapp>В Django 1. 8+ вы можете указать имя:
python manage.py makemigrations --empty <yourapp> --name load_intial_data -
Отредактируйте файл миграции
<yourapp>/migrations/0002_auto_xxx.py2.1. Пользовательская реализация, вдохновленная Django '
loaddata(первоначальный ответ):import os from sys import path from django.core import serializers fixture_dir = os.path.abspath(os.path.join(os.path.dirname(__file__), '../fixtures')) fixture_filename = 'initial_data.json' def load_fixture(apps, schema_editor): fixture_file = os.path.join(fixture_dir, fixture_filename) fixture = open(fixture_file, 'rb') objects = serializers.deserialize('json', fixture, ignorenonexistent=True) for obj in objects: obj.save() fixture.close() def unload_fixture(apps, schema_editor): "Brutally deleting all entries for this model..." MyModel = apps.get_model("yourapp", "ModelName") MyModel.objects.all().delete() class Migration(migrations.Migration): dependencies = [ ('yourapp', '0001_initial'), ] operations = [ migrations.RunPython(load_fixture, reverse_code=unload_fixture), ]2.2. Более простое решение для
load_fixture(согласно предложению @juliocesar):from django.core.management import call_command fixture_dir = os.path.abspath(os.path.join(os.path.dirname(__file__), '../fixtures')) fixture_filename = 'initial_data.json' def load_fixture(apps, schema_editor): fixture_file = os.path.join(fixture_dir, fixture_filename) call_command('loaddata', fixture_file)Полезно, если вы хотите использовать пользовательский каталог.
2,3. Простейший: вызов
loaddataсapp_labelзагрузят светильники из<yourapp>fixturesDir автоматически:from django.core.management import call_command fixture = 'initial_data' def load_fixture(apps, schema_editor): call_command('loaddata', fixture, app_label='yourapp')Если вы не укажете
app_label, LoadData будет пытаться загрузитьfixtureимя файл из всех приложений приборов каталогов (которые вы, вероятно, не хотите). -
Запустить его
python manage.py migrate <yourapp>
-
0Код в функции
load_fixtureможно улучшить, просто вызвавcall_command('loaddata', fixture_file) -
0Спасибо за комментарий. Я не помню точно, почему я сделал это таким образом (имитируя
loaddata), вместо непосредственного вызоваloaddata. Я помню проблемы сloaddataне работали "как ожидалось" при выполнении полной миграции.python manage.py migrate <yourapp>будет работать отлично, как иpython manage.py loaddata, ноpython manage.py migrateне сможет найти файлpython manage.py loaddata. Может быть, я делал что-то не так.
Укороченная версия
Вам НЕ следует использовать loaddata управления loaddata непосредственно при переносе данных.
# Bad example for a data migration
from django.db import migrations
from django.core.management import call_command
def load_fixture(apps, schema_editor):
# No, it wrong. DON'T DO THIS!
call_command('loaddata', 'your_data.json', app_label='yourapp')
class Migration(migrations.Migration):
dependencies = [
# Dependencies to other migrations
]
operations = [
migrations.RunPython(load_fixture),
]
Длинная версия
loaddata использует django.core.serializers.python.Deserializer который использует самые современные модели для десериализации исторических данных в процессе миграции. Это неправильное поведение.
Например, предполагается, что существует миграция данных, которая использует loaddata управления loaddata для загрузки данных из осветителя, и она уже применяется в вашей среде разработки.
Позже вы решаете добавить новое обязательное поле в соответствующую модель, поэтому вы делаете это и делаете новую миграцию для своей обновленной модели (и, возможно, предоставляете одноразовое значение для нового поля, когда ./manage.py makemigrations запрашивает вас).
Вы запускаете следующую миграцию, и все хорошо.
Наконец, вы закончили разработку приложения Django и развернули его на рабочем сервере. Теперь пришло время запустить все миграции с нуля в производственной среде.
Однако перенос данных не выполняется. Это потому, что десериализованная модель из команды loaddata, представляющая текущий код, не может быть сохранена с пустыми данными для нового обязательного поля, которое вы добавили. В оригинальном светильнике отсутствуют необходимые данные!
Но даже если вы обновите прибор с необходимыми данными для нового поля, миграция данных все равно не удастся. Когда выполняется миграция данных, следующая миграция, которая добавляет соответствующий столбец в базу данных, еще не применяется. Вы не можете сохранить данные в столбце, который не существует!
Вывод: при переносе данных команда loaddata вносит потенциальное несоответствие между моделью и базой данных. Вы определенно не должны использовать его непосредственно при переносе данных.
Решение
loaddata использует функцию django.core.serializers.python._get_model для получения соответствующей модели из осветителя, которая будет возвращать самую последнюю версию модели. Мы должны сделать это, чтобы получить историческую модель.
(Следующий код работает для Django 1.8.x)
# Good example for a data migration
from django.db import migrations
from django.core.serializers import base, python
from django.core.management import call_command
def load_fixture(apps, schema_editor):
# Save the old _get_model() function
old_get_model = python._get_model
# Define new _get_model() function here, which utilizes the apps argument to
# get the historical version of a model. This piece of code is directly stolen
# from django.core.serializers.python._get_model, unchanged. However, here it
# has a different context, specifically, the apps variable.
def _get_model(model_identifier):
try:
return apps.get_model(model_identifier)
except (LookupError, TypeError):
raise base.DeserializationError("Invalid model identifier: '%s'" % model_identifier)
# Replace the _get_model() function on the module, so loaddata can utilize it.
python._get_model = _get_model
try:
# Call loaddata command
call_command('loaddata', 'your_data.json', app_label='yourapp')
finally:
# Restore old _get_model() function
python._get_model = old_get_model
class Migration(migrations.Migration):
dependencies = [
# Dependencies to other migrations
]
operations = [
migrations.RunPython(load_fixture),
]
-
0Rockallite, вы делаете очень сильную точку. Ваш ответ заставил меня задуматься, а будет ли решение 2.1 из ответа @ n__o / @ mlissner, основанного на
objects = serializers.deserialize('json', fixture, ignorenonexistent=True)страдать от той же проблемы, что иloaddata? Илиignorenonexistent=Trueпокрывает все возможные проблемы? -
5Если вы посмотрите на источник , то обнаружите, что аргумент
ignorenonexistent=Trueимеет два эффекта: 1) он игнорирует модели прибора, которых нет в самых последних определениях модели, 2) он игнорирует поля модели прибора которые не в самом актуальном соответствующем определении модели. Ни один из них не справляется с ситуацией нового обязательного поля в модели . Так что, да, я думаю, что он страдает той же проблемой, что и обычные данныеloaddata.
Вдохновленный некоторыми комментариями (а именно n__o) и тем, что у меня много файлов initial_data.* Распределенных по нескольким приложениям, я решил создать приложение Django, которое облегчит создание этих миграций данных.
Используя django -igration-fixture, вы можете просто запустить следующую команду управления, и она INSTALLED_APPS все ваши INSTALLED_APPS для файлов initial_data.* И превратит их в перенос данных.
./manage.py create_initial_data_fixtures
Migrations for 'eggs':
0002_auto_20150107_0817.py:
Migrations for 'sausage':
Ignoring 'initial_data.yaml' - migration already exists.
Migrations for 'foo':
Ignoring 'initial_data.yaml' - not migrated.
Смотрите django -igration-fixture для инструкций по установке/использованию.
Лучший способ загрузить исходные данные в переносимые приложения - это миграция данных (также рекомендуется в документах). Преимущество заключается в том, что крепление таким образом загружается как во время испытаний, так и при производстве.
@n__o предложила переопределить команду loaddata в миграции. Однако в моих тестах вызов команды loaddata также отлично работает. Таким образом, весь процесс:
-
Создайте файл fixture в
<yourapp>/fixtures/initial_data.json -
Создайте пустую миграцию:
python manage.py makemigrations --empty <yourapp> -
Измените файл миграции /migrations/ 0002_auto_xxx.py
from django.db import migrations from django.core.management import call_command def loadfixture(apps, schema_editor): call_command('loaddata', 'initial_data.json') class Migration(migrations.Migration): dependencies = [ ('<yourapp>', '0001_initial'), ] operations = [ migrations.RunPython(loadfixture), ]
-
0Я попробую это как можно скорее, но если это сработает, это будет гораздо более простым решением. Спасибо !
-
3Команда
loaddataне подходит для использования при переносе данных, так как она используетdjango.core.serializers.python.Deserializerкоторый использует самые современные модели для десериализации исторических данных. Например, если вы добавите новое обязательное поле в модель в более поздней миграции, а затем запустите миграции из новой базы данных, десериализованная модель не удастся сохранить, поскольку новое поле не будет назначено с исторической фикстурой. Даже если вы обновите прибор с новыми полевыми данными, новый столбец еще не будет добавлен в базу данных во время выполнения миграции, поэтому он тоже не удастся.
Чтобы предоставить вашей базе данных некоторые исходные данные, напишите перенос данных. В процессе переноса данных используйте функцию RunPython для загрузки ваших данных.
Не записывайте команду loaddata, так как этот способ устарел.
Ваши миграции данных будут выполняться только один раз. Миграции - упорядоченная последовательность миграций. Когда выполняется миграция 003_xxxx.py, миграции django записывают в базу данных, что это приложение переносится до этого (003), и будут выполняться только следующие миграции.
-
0Таким образом, вы предлагаете мне повторять вызовы
myModel.create(...)(или использовать цикл) в функции RunPython? -
0в значительной степени да. Трансациональные базы данных отлично с этим справятся :)
Представленные выше решения для меня, к сожалению, не работали. Я обнаружил, что каждый раз, когда я меняю свои модели, мне приходится обновлять свои светильники. В идеале я бы вместо этого написал миграцию данных, чтобы модифицировать созданные данные и данные, загруженные с помощью файла, таким же образом.
Чтобы облегчить это я написал краткую функцию, которая будет выглядеть в каталоге fixtures текущего приложения и загружать прибор. Поместите эту функцию в перемещение в точке истории модели, которая соответствует полям в миграции.
-
0Спасибо за это! Я написал версию, которая работает с Python 3 (и проходит наш строгий Pylint). Вы можете использовать его как фабрику с
RunPython(load_fixture('badger', 'stoat')). gist.github.com/danni/1b2a0078e998ac080111
На Django 2.1 я хотел загрузить некоторые модели (например, названия стран) с исходными данными.
Но я хотел, чтобы это происходило автоматически сразу после выполнения первоначальных миграций.
Поэтому я подумал, что было бы здорово иметь папку sql/ внутри каждого приложения, которое требовало загрузки начальных данных.
Тогда в этой папке sql/ меня будут файлы .sql с необходимыми DML для загрузки исходных данных в соответствующие модели, например:
INSERT INTO appName_modelName(fieldName)
VALUES
("country 1"),
("country 2"),
("country 3"),
("country 4");
Чтобы быть более наглядным, вот как должно выглядеть приложение, содержащее папку sql/: 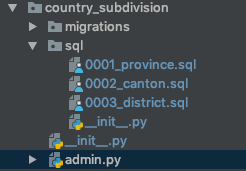
Также я нашел несколько случаев, когда мне нужно было выполнить сценарии sql в определенном порядке. Поэтому я решил поставить перед именами файлов последовательный номер, как показано на рисунке выше.
Затем мне понадобился способ автоматической загрузки любых SQLs доступных в любой папке приложения, с помощью команды python manage.py migrate.
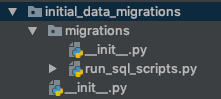
Поэтому я создал другое приложение с именем initial_data_migrations а затем добавил это приложение в список INSTALLED_APPS в файле settings.py. Затем я создал папку migrations внутри и добавил файл с именем run_sql_scripts.py (который на самом деле является пользовательской миграцией). Как видно на рисунке ниже:
Я создал run_sql_scripts.py чтобы он позаботился о запуске всех сценариев sql доступных в каждом приложении. Затем он запускается, когда кто-то запускает python manage.py migrate. Эта пользовательская migration также добавляет вовлеченные приложения в качестве зависимостей, таким образом, она пытается выполнить операторы sql только после того, как требуемые приложения выполнили свои миграции 0001_initial.py (мы не хотим пытаться выполнить оператор SQL для несуществующей таблицы).
Вот источник этого скрипта:
import os
import itertools
from django.db import migrations
from YourDjangoProjectName.settings import BASE_DIR, INSTALLED_APPS
SQL_FOLDER = "/sql/"
APP_SQL_FOLDERS = [
(os.path.join(BASE_DIR, app + SQL_FOLDER), app) for app in INSTALLED_APPS
if os.path.isdir(os.path.join(BASE_DIR, app + SQL_FOLDER))
]
SQL_FILES = [
sorted([path + file for file in os.listdir(path) if file.lower().endswith('.sql')])
for path, app in APP_SQL_FOLDERS
]
def load_file(path):
with open(path, 'r') as f:
return f.read()
class Migration(migrations.Migration):
dependencies = [
(app, '__first__') for path, app in APP_SQL_FOLDERS
]
operations = [
migrations.RunSQL(load_file(f)) for f in list(itertools.chain.from_iterable(SQL_FILES))
]
Я надеюсь, что кто-то найдет это полезным, у меня это сработало! Если у вас есть какие-либо вопросы, пожалуйста, дайте мне знать.
ПРИМЕЧАНИЕ. Возможно, это не лучшее решение, так как я только начинаю работать с django, но все же хотел бы поделиться с вами всеми этими практическими рекомендациями, поскольку я не нашел много информации, пока гуглял об этом.
По-моему, светильники немного плохие. Если ваша база данных будет меняться часто, то держать ее в курсе событий скоро будет кошмар. Собственно, это не только мое мнение, в книге "Два совок Джанго" это объяснялось намного лучше.
Вместо этого я напишу файл Python, чтобы обеспечить первоначальную настройку. Если вам нужно что-то еще, я предлагаю вам посмотреть Factory boy.
Если вам нужно перенести некоторые данные, вы должны использовать миграцию данных.
Там также "Записать свои светильники, использовать фабрики моделей" об использовании светильников.
-
0Я согласен с вашей точкой зрения «трудно поддерживать, если частые изменения», но здесь это приспособление направлено только на предоставление начальных (и минимальных) данных при установке проекта ...
-
0Это для единовременной загрузки данных, которая, если она выполняется в контексте миграций, имеет смысл. Поскольку, если он находится в процессе миграции, не нужно вносить изменения в данные JSON. Любые изменения схемы, которые требуют изменений данных в дальнейшем, должны обрабатываться с помощью другой миграции (в этот момент другие данные могут быть в базе данных, которые также необходимо будет изменить).
Ещё вопросы
- 0Как предотвратить повторную инициализацию Google Hash
- 1Почему значение в List <T> изменяется, если есть копии в ObservableCollection?
- 0Масштабирование фона SVG
- 0Получить все с отличным идентификатором пользователя и порядком по общему счету
- 0Получить счет из двух разных таблиц на основе datetime в MySQL
- 1Привязать строку из .resx ResourceDictionary к TextBlock.Text, используя ключ индекса
- 1Как вывести тип аргумента? расширяет класс в объявлении интерфейса
- 0boost :: mutex поддерживает try_lock_for в Visual Studio, но не в Xcode
- 0Функция клика Jquery работает только дважды
- 0Правильный SQL-запрос - Обновление записей, где заголовок совпадает
- 1Установить кортеж в качестве имени столбца в Pandas
- 1Uncaught Ошибка: process.binding не поддерживается (browserify + selenium-webdriver)
- 1Как панды заменяют значения NaN средним значением, используя groupby [duplicate]
- 1Добавление значений, возвращаемых SQL-запросом, чтобы получить итог?
- 0пакет udp не получен в QThread
- 0MySQL: как отсортировать некоторые записи в ASC, а некоторые в порядке DESC, основываясь на значении другого поля
- 1Очевидное загрязнение несколькими прокси-объектами для одной цели
- 1как получить значения строки, когда флажок установлен в gridview
- 0Как я могу непрерывно запускать функцию после добавления данных и завершения работы с этими данными
- 0Создание представления в MySQL, которое должно обновляться еженедельно
- 0Проверка регулярных выражений для смешанных дробей - Visual C ++ 2012
- 1Хранить данные из твиттера api javascript (nodejs)
- 0Как вызвать myScroll.scrollToElement при загрузке страницы
- 0Что на самом деле означает «установить библиотеку» в Linux?
- 1Сделайте ссылку недоступной при некоторых условиях в asp.net
- 0Вставка данных из базы данных в массив и внедрение этих данных в текстовую область
- 0Google Map API скачать карту
- 0MySQL объявление переменной, вызывающей синтаксическую ошибку
- 0Как отобразить результаты RSS ленты в списке JQuery
- 0Маршрутизация пользовательского интерфейса с корневым состоянием не разрешается до дочернего контроллера состояния
- 1Обращение к члену в качестве переменной в Discord.py
- 1Как сделать AppBarLayout плавающим над контентом, как в недавнем дизайне Google
- 1Изменить цвет сюжета FEVD
- 0Динамический метатег с angularJS
- 1C # - Backgroundworker и REST сервис
- 1Как поделиться глубокой ссылкой в соцсетях на реакцию родных
- 0как передать max_streak_length из командной строки
- 0Форма jQuery вылетает при щелчке переключателя
- 1Найти корень производной абсолютного значения комплексного числа в симпы
- 0Добавить значение даты и времени
- 0создание файла для перенаправления вывода оболочки
- 1Java BufferedReader FileReader проблема
- 0Facebook API - реализация приглашения друзей, как на Quora
- 0Как сделать ссылку кликабельной или не кликабельной по тексту в текстовой области?
- 0Передать пользовательскую переменную в анонимную функцию щелчка jQuery
- 0JQuery Как процитировать динамическую строку
- 0Как я могу получить все выбранные значения флажка при отправке действия с использованием угловых JS?
- 1Как бороться с зависимыми полями при сериализации?
- 1Получить все div под div с известным идентификатором и перебрать его
- 0Angular SyntaxError: Неожиданный токен}
