Как объединить (объединить) фреймы данных (внутренний, внешний, левый, правый)
Учитывая два кадра данных:
df1 = data.frame(CustomerId = c(1:6), Product = c(rep("Toaster", 3), rep("Radio", 3)))
df2 = data.frame(CustomerId = c(2, 4, 6), State = c(rep("Alabama", 2), rep("Ohio", 1)))
df1
# CustomerId Product
# 1 Toaster
# 2 Toaster
# 3 Toaster
# 4 Radio
# 5 Radio
# 6 Radio
df2
# CustomerId State
# 2 Alabama
# 4 Alabama
# 6 Ohio
Как я могу создать стиль базы данных, т.е. стиль sql, присоединяется? То есть, как мне получить:
- внутреннее соединение
df1иdf2:
Верните только строки, в которых левая таблица имеет соответствующие ключи в правой таблице. - внешнее соединение
df1иdf2:
Возвращает все строки из обеих таблиц, объединяет записи слева, которые имеют соответствующие ключи в правой таблице. - A левое внешнее соединение (или просто левое соединение)
df1иdf2
Верните все строки из левой таблицы и любые строки с соответствующими ключами из правой таблицы. - A правое внешнее соединение
df1иdf2
Верните все строки из правой таблицы и любые строки с соответствующими ключами из левой таблицы.
Дополнительный кредит:
Как я могу выполнить оператор выбора стиля SQL?
-
3stat545-ubc.github.io/bit001_dplyr-cheatsheet.html ← мой любимый ответ на этот вопросisomorphismes
-
0Преобразование данных с помощью шпаргалки dplyr, созданной и поддерживаемой RStudio, также содержит хорошую инфографику о том, как работают объединения, в dplyr rstudio.com/resources/cheatsheetsArthur Yip
13 ответов
Используя функцию merge и ее необязательные параметры:
Внутреннее соединение: merge(df1, df2) будет работать для этих примеров, потому что R автоматически объединяет кадры по общим именам переменных, но вы, скорее всего, захотите указать merge(df1, df2, by = "CustomerId") чтобы убедиться, что вы были сопоставлены только те поля, которые вы хотели. Вы также можете использовать параметры by.x и by.y если совпадающие переменные имеют разные имена в разных фреймах данных.
Внешнее соединение: merge(x = df1, y = df2, by = "CustomerId", all = TRUE)
Слева: merge(x = df1, y = df2, by = "CustomerId", all.x = TRUE)
Справа: merge(x = df1, y = df2, by = "CustomerId", all.y = TRUE)
Перекрестное соединение: merge(x = df1, y = df2, by = NULL)
Как и в случае внутреннего соединения, вы, вероятно, захотите явно передать "CustomerId" в R в качестве соответствующей переменной. Я думаю, что почти всегда лучше явно указывать идентификаторы, по которым вы хотите объединить; безопаснее, если входные данные изменяются неожиданно и их легче читать позже.
Вы можете объединить в несколько столбцов, давая by вектора, например, by = c("CustomerId", "OrderId").
Если имена столбцов для объединения не совпадают, вы можете указать, например, by.x = "CustomerId_in_df1", by.y = "CustomerId_in_df2" где CustomerId_in_df1 - это имя столбца в первом фрейме данных, а CustomerId_in_df2 - это имя столбца во втором фрейме данных. (Это также могут быть векторы, если вам нужно объединить несколько столбцов.)
-
2@MattParker Я использовал пакет sqldf для целого ряда сложных запросов к фреймам данных, мне действительно нужно было выполнить самопересекающееся соединение (т.е. сам кросс-фрейм data.frame). Интересно, как он сравнивается с точки зрения производительности ... . ???
-
8@ADP Я никогда не использовал sqldf, поэтому я не уверен в скорости. Если производительность для вас является серьезной проблемой, вам также следует взглянуть на пакет
data.table- это совершенно новый набор синтаксиса соединения, но он значительно быстрее, чем все, о чем мы здесь говорим.
Я бы рекомендовал проверить пакет Gabor Grothendieck sqldf, который позволяет вам выражать эти операции в SQL.
library(sqldf)
## inner join
df3 <- sqldf("SELECT CustomerId, Product, State
FROM df1
JOIN df2 USING(CustomerID)")
## left join (substitute 'right' for right join)
df4 <- sqldf("SELECT CustomerId, Product, State
FROM df1
LEFT JOIN df2 USING(CustomerID)")
Я считаю синтаксис SQL более простым и естественным, чем его эквивалент R (но это может просто отражать смещение RDBMS).
Подробнее о объединениях см. Gabor sqldf GitHub.
Для внутреннего соединения существует подход data.table, который очень эффективен для времени и памяти (и необходим для некоторых более крупных data.frames):
library(data.table)
dt1 <- data.table(df1, key = "CustomerId")
dt2 <- data.table(df2, key = "CustomerId")
joined.dt1.dt.2 <- dt1[dt2]
merge также работает с data.tables(поскольку он является общим и вызывает merge.data.table)
merge(dt1, dt2)
data.table, зарегистрированный в stackoverflow:
Как выполнить операцию слияния data.table
Перевод SQL-соединений по внешним ключам в синтаксис R data.table
Эффективные альтернативы слиянию для больших данных. Кадры R
Как сделать базовое левое внешнее соединение с data.table в R?
Еще один вариант - это функция join, найденная в пакете plyr
library(plyr)
join(df1, df2,
type = "inner")
# CustomerId Product State
# 1 2 Toaster Alabama
# 2 4 Radio Alabama
# 3 6 Radio Ohio
Параметры type: inner, left, right, full.
Из ?join: В отличие от merge, [join] сохраняет порядок x независимо от того, какой тип соединения используется.
-
8+1 за упоминание
plyr::join. Микробенчмаркинг показывает, что он работает примерно в 3 раза быстрее, чемmerge. -
18Однако
data.tableнамного быстрее, чем оба. Существует также большая поддержка в SO, я не вижу, чтобы многие авторы пакетов отвечали на вопросы здесь так часто, какdata.tableили участники.
Вы также можете объединиться, используя Hadley Wickham awesome dplyr.
library(dplyr)
#make sure that CustomerId cols are both type numeric
#they ARE not using the provided code in question and dplyr will complain
df1$CustomerId <- as.numeric(df1$CustomerId)
df2$CustomerId <- as.numeric(df2$CustomerId)
Мутирующие соединения: добавьте столбцы в df1, используя совпадения в df2
#inner
inner_join(df1, df2)
#left outer
left_join(df1, df2)
#right outer
right_join(df1, df2)
#alternate right outer
left_join(df2, df1)
#full join
full_join(df1, df2)
Фильтрация соединений: отфильтровать строки в df1, не изменять столбцы
semi_join(df1, df2) #keep only observations in df1 that match in df2.
anti_join(df1, df2) #drops all observations in df1 that match in df2.
-
16Зачем вам нужно конвертировать
CustomerIdв числовой? Я не вижу упоминаний в документации (как дляplyrи дляdplyr) об этом типе ограничений. Будет ли ваш код работать неправильно, если столбец слияния будет иметьcharacterтип (особенно интересуетplyr)? Я что-то пропустил? -
0Можно ли использовать semi_join (df1, df2, df3, df4), чтобы сохранить только наблюдения в df1, которые соответствуют остальным столбцам?
Есть несколько хороших примеров этого в R Wiki. Я украду пару здесь:
Метод слияния
Поскольку ваши ключи называются одинаковыми, короткий способ сделать внутреннее соединение - merge():
merge(df1,df2)
полное внутреннее соединение (все записи из обеих таблиц) может быть создано с помощью ключевого слова "все":
merge(df1,df2, all=TRUE)
левое внешнее объединение df1 и df2:
merge(df1,df2, all.x=TRUE)
правое внешнее объединение df1 и df2:
merge(df1,df2, all.y=TRUE)
вы можете перевернуть их, пощекотать их и протрите их, чтобы получить два других внешних соединения, о которых вы спрашивали:)
Метод подстроки
Левое внешнее соединение с df1 слева с использованием метода подстроки:
df1[,"State"]<-df2[df1[ ,"Product"], "State"]
Другая комбинация внешних объединений может быть создана путем изменения примера нижнего индекса внешнего внешнего соединения. (да, я знаю, что эквивалент слова "Я оставлю это как упражнение для читателя..." )
-
1Ссылка "R Wiki" не работает.
Новое в 2014 году:
Особенно, если вы также заинтересованы в манипулировании данными в целом (включая сортировку, фильтрацию, подмножество, подведение итогов и т.д.), вы должны обязательно взглянуть на dplyr, который включает в себя множество функций, предназначенных для облегчения ваша работа специально с кадрами данных и некоторыми другими типами баз данных. Он даже предлагает довольно сложный SQL-интерфейс и даже функцию для преобразования (большинства) SQL-кода непосредственно в R.
Четыре функции, связанные с соединением в пакете dplyr, (цитата):
-
inner_join(x, y, by = NULL, copy = FALSE, ...): вернуть все строки из x, где в y есть соответствующие значения, а все столбцы от x и y -
left_join(x, y, by = NULL, copy = FALSE, ...): вернуть все строки из x и все столбцы из x и y -
semi_join(x, y, by = NULL, copy = FALSE, ...): вернуть все строки из x, где есть соответствующие значения в y, сохраняя только столбцы от x. -
anti_join(x, y, by = NULL, copy = FALSE, ...): вернуть все строки из x где в y нет совпадающих значений, сохраняя только столбцы от x
Все здесь очень подробно.
Выбор столбцов можно сделать с помощью select(df,"column"). Если этого недостаточно для SQL-ish, то есть функция sql(), в которую вы можете ввести код SQL как есть, и будет выполнять указанную вами операцию так же, как вы писались в R все время (для получения дополнительной информации, обратитесь к dplyr/database vignette). Например, если применить правильно, sql("SELECT * FROM hflights") выберет все столбцы из таблицы dplyr "hflights" ( "tbl" ).
-
0Определенно лучшее решение, учитывая важность, которую пакет dplyr приобрел за последние два года.
Обновление методов data.table для объединения наборов данных. Ниже приведены примеры для каждого типа соединения. Существует два метода: один из [.data.table при передаче второго data.table в качестве первого аргумента подмножеству, другой способ - использовать функцию merge которая отправляет быстрый метод data.table.
df1 = data.frame(CustomerId = c(1:6), Product = c(rep("Toaster", 3), rep("Radio", 3)))
df2 = data.frame(CustomerId = c(2L, 4L, 7L), State = c(rep("Alabama", 2), rep("Ohio", 1))) # one value changed to show full outer join
library(data.table)
dt1 = as.data.table(df1)
dt2 = as.data.table(df2)
setkey(dt1, CustomerId)
setkey(dt2, CustomerId)
# right outer join keyed data.tables
dt1[dt2]
setkey(dt1, NULL)
setkey(dt2, NULL)
# right outer join unkeyed data.tables - use 'on' argument
dt1[dt2, on = "CustomerId"]
# left outer join - swap dt1 with dt2
dt2[dt1, on = "CustomerId"]
# inner join - use 'nomatch' argument
dt1[dt2, nomatch=NULL, on = "CustomerId"]
# anti join - use '!' operator
dt1[!dt2, on = "CustomerId"]
# inner join - using merge method
merge(dt1, dt2, by = "CustomerId")
# full outer join
merge(dt1, dt2, by = "CustomerId", all = TRUE)
# see ?merge.data.table arguments for other cases
Ниже бенчмарк тестирует базу R, sqldf, dplyr и data.table.
Контрольные тесты наборов данных без ключа. Для sqldf и data.table также индексы тестируются как отдельные тайминги. База R и dplyr не имеют индексов.
Тестирование выполняется для наборов данных 50M-1, в столбце объединения есть общие значения 50M-2, поэтому каждый сценарий (внутренний, левый, правый, полный) можно протестировать, а объединение все еще не является тривиальным. Это тип объединения, который хорошо подчеркивает алгоритмы объединения. По состоянию на sqldf:0.4.11, dplyr:0.7.8, data.table:1.12.0.
# inner
Unit: seconds
expr min lq mean median uq max neval
base 111.66266 111.66266 111.66266 111.66266 111.66266 111.66266 1
sqldf 624.88388 624.88388 624.88388 624.88388 624.88388 624.88388 1
isqldf 614.69304 614.69304 614.69304 614.69304 614.69304 614.69304 1
dplyr 51.91233 51.91233 51.91233 51.91233 51.91233 51.91233 1
DT 10.40552 10.40552 10.40552 10.40552 10.40552 10.40552 1
IDT 10.24206 10.24206 10.24206 10.24206 10.24206 10.24206 1
# left
Unit: seconds
expr min lq mean median uq max
base 142.782030 142.782030 142.782030 142.782030 142.782030 142.782030
sqldf 613.917109 613.917109 613.917109 613.917109 613.917109 613.917109
isqldf 624.641976 624.641976 624.641976 624.641976 624.641976 624.641976
dplyr 49.711912 49.711912 49.711912 49.711912 49.711912 49.711912
DT 9.674348 9.674348 9.674348 9.674348 9.674348 9.674348
IDT 11.913815 11.913815 11.913815 11.913815 11.913815 11.913815
# right
Unit: seconds
expr min lq mean median uq max
base 122.366301 122.366301 122.366301 122.366301 122.366301 122.366301
sqldf 611.119157 611.119157 611.119157 611.119157 611.119157 611.119157
isqldf 617.698158 617.698158 617.698158 617.698158 617.698158 617.698158
dplyr 50.384841 50.384841 50.384841 50.384841 50.384841 50.384841
DT 9.899145 9.899145 9.899145 9.899145 9.899145 9.899145
IDT 9.402034 9.402034 9.402034 9.402034 9.402034 9.402034
# full
Unit: seconds
expr min lq mean median uq max neval
base 141.79464 141.79464 141.79464 141.79464 141.79464 141.79464 1
dplyr 94.66436 94.66436 94.66436 94.66436 94.66436 94.66436 1
DT 21.62573 21.62573 21.62573 21.62573 21.62573 21.62573 1
IDT 20.59082 20.59082 20.59082 20.59082 20.59082 20.59082 1
Имейте в data.table что существуют другие типы объединений, которые вы можете выполнять с помощью data.table:
- обновить при объединении - если вы хотите искать значения из другой таблицы в вашей основной таблице
- агрегировать при объединении - если вы хотите агрегировать по ключу, к которому присоединяетесь, вам не нужно материализовать все результаты объединения
- перекрывающееся соединение - если вы хотите объединить по диапазонам
- Скользящее соединение - если вы хотите, чтобы объединение могло соответствовать значениям из предыдущих/следующих строк, прокручивая их вперед или назад
- неравное соединение - если ваше условие соединения не равно
Код для воспроизведения:
library(microbenchmark)
library(sqldf)
library(dplyr)
library(data.table)
sapply(c("sqldf","dplyr","data.table"), packageVersion, simplify=FALSE)
n = 5e7
set.seed(108)
df1 = data.frame(x=sample(n,n-1L), y1=rnorm(n-1L))
df2 = data.frame(x=sample(n,n-1L), y2=rnorm(n-1L))
dt1 = as.data.table(df1)
dt2 = as.data.table(df2)
idf1 = copy(df1)
sqldf("create index idf1_x on idf1(x);")
idf2 = copy(df2)
sqldf("create index idf2_x on idf2(x);")
idt1 = copy(dt1)
setindexv(idt1, "x")
idt2 = copy(dt2)
setindexv(idt2, "x")
mb = list()
# inner join
microbenchmark(times = 1L,
base = merge(df1, df2, by = "x"),
sqldf = sqldf("SELECT * FROM df1 INNER JOIN df2 ON df1.x = df2.x"),
isqldf = sqldf("SELECT * FROM main.'idf1' INNER JOIN main.'idf2' ON main.idf1.x = main.'idf2'.x"),
dplyr = inner_join(df1, df2, by = "x"),
DT = dt1[dt2, nomatch=NULL, on = "x"],
IDT = idt1[idt2, nomatch=NULL, on = "x"]) -> mb$inner
# left outer join
microbenchmark(times = 1L,
base = merge(df1, df2, by = "x", all.x = TRUE),
sqldf = sqldf("SELECT * FROM df1 LEFT OUTER JOIN df2 ON df1.x = df2.x"),
isqldf = sqldf("SELECT * FROM main.'idf1' LEFT OUTER JOIN main.'idf2' ON main.'idf1'.x = main.'idf2'.x"),
dplyr = left_join(df1, df2, by = c("x"="x")),
DT = dt2[dt1, on = "x"],
IDT = idt2[idt1, on = "x"]) -> mb$left
# right outer join
microbenchmark(times = 1L,
base = merge(df1, df2, by = "x", all.y = TRUE),
sqldf = sqldf("SELECT * FROM df2 LEFT OUTER JOIN df1 ON df2.x = df1.x"),
isqldf = sqldf("SELECT * FROM main.'idf2' LEFT OUTER JOIN main.'idf1' ON main.'idf2'.x = main.'idf1'.x"),
dplyr = right_join(df1, df2, by = "x"),
DT = dt1[dt2, on = "x"],
IDT = idt1[idt2, on = "x"]) -> mb$right
# full outer join
microbenchmark(times = 1L,
base = merge(df1, df2, by = "x", all = TRUE),
dplyr = full_join(df1, df2, by = "x"),
DT = merge(dt1, dt2, by = "x", all = TRUE),
IDT = merge(idt1, idt2, by = "x", all = TRUE)) -> mb$full
lapply(mb, print) -> nul
-
0Стоит ли добавлять пример, показывающий, как использовать разные имена столбцов в
on =? -
1@Symbolix мы можем ждать 1.9.8 релиза , как это добавит не-операторы присоединяются к следу , чтобы
onарг
При объединении двух кадров данных с ~ 1 миллионом строк каждый, один с двумя столбцами, а другой с ~ 20, я неожиданно нашел merge(..., all.x = TRUE, all.y = TRUE) быстрее, чем dplyr::full_join(). Это с dplyr v0.4
Слияние занимает ~ 17 секунд, full_join занимает ~ 65 секунд.
Некоторая еда, хотя, поскольку я обычно по умолчанию dplyr для задач манипуляции.
dplyr с 0,4 реализовал все те объединения, в том числе external_join, но стоит отметить, что для первых нескольких выпусков он использовал не предлагать external_join, и в результате было довольно много очень плохого взломанного временного кода пользователя, который довольно долго плавал ( вы все равно можете найти это в ответах SO и Kaggle с того периода).
Связанные с выпуском выпуски:
- Обработка для типа POSIXct, часовых поясов, дубликатов, разных уровней факторов. Лучшие ошибки и предупреждения.
- Новый аргумент суффикса для контроля того, какие суффиксные имена дублированных переменных получают (# 1296)
- Внедрить правое соединение и внешнее соединение (# 96)
- Мутирующие объединения, которые добавляют новые переменные в одну таблицу из совпадающих строк в другой. Фильтрация соединений, которые фильтруют наблюдения из одной таблицы в зависимости от того, соответствуют ли они наблюдению в другой таблице.
- Может теперь left_join различными переменными в каждой таблице: df1%>% left_join (df2, c ("var1" = "var2"))
- * _join() больше не переупорядочивает имена столбцов (# 324)
v0.1.3 (4/2014)
- имеет inner_join, left_join, semi_join, anti_join
- external_join еще не реализован, backback использует base :: merge() (или plyr :: join())
- еще не реализовали right_join и external_join
- Хэдли упомянул о других преимуществах здесь
- одно небольшое слияние функций в настоящее время имеет то, что dplyr не является способностью иметь отдельные столбцы by.x, by.y, например , Pandon pandas.
Методы обхода на один комментарий в этом вопросе:
- right_join (x, y) совпадает с left_join (y, x) в терминах строк, только столбцы будут разными порядками. Легко работать с select (new_column_order)
- external_join - это в основном union (left_join (x, y), right_join (x, y)) - то есть сохранить все строки в обоих кадрах данных.
-
3Этот ответ должен быть либо обновлен, либо удален.
full_joinиright_joinбыли частьюdplyrтечение почти 2 лет и разделяли имена столбцов x и y еще дольше. Мадж и Эндрю Барр, кажется, хорошоdplyrметодыdplyr... -
1@ Грегор: нет, это не должно быть удалено. Для пользователей R важно знать, что возможности объединения отсутствовали в течение многих лет, так как большая часть кода содержит обходные пути или специальные ручные реализации, или рекламное приложение с векторами индексов, или, что еще хуже, избегает использования этих пакетов или операции на всех. Каждую неделю я вижу такие вопросы на SO. Мы будем устранять путаницу на долгие годы.
В случае левого соединения с мощностью 0..*:0..1 или правым соединением с мощностью 0..1:0..* можно назначить односторонние столбцы из столяра (таблицы 0..1) непосредственно на joinee (таблица 0..*) и тем самым избежать создания совершенно новой таблицы данных. Для этого требуется сопоставление ключевых столбцов от joinee в столяре и индексация + упорядочение строк joiner соответственно для назначения.
Если ключ является одним столбцом, мы можем использовать один вызов match(), чтобы выполнить сопоставление. В этом случае я расскажу об этом в ответ.
Вот пример, основанный на OP, за исключением того, что я добавил дополнительную строку в df2 с идентификатором 7, чтобы проверить случай несогласованного ключа в столяре. Это эффективно df1 left join df2:
df1 <- data.frame(CustomerId=1:6,Product=c(rep('Toaster',3L),rep('Radio',3L)));
df2 <- data.frame(CustomerId=c(2L,4L,6L,7L),State=c(rep('Alabama',2L),'Ohio','Texas'));
df1[names(df2)[-1L]] <- df2[match(df1[,1L],df2[,1L]),-1L];
df1;
## CustomerId Product State
## 1 1 Toaster <NA>
## 2 2 Toaster Alabama
## 3 3 Toaster <NA>
## 4 4 Radio Alabama
## 5 5 Radio <NA>
## 6 6 Radio Ohio
В приведенном выше я жестко закодировал предположение, что ключевой столбец является первым столбцом обеих входных таблиц. Я бы сказал, что в целом это не необоснованное предположение, поскольку, если у вас есть data.frame с ключевым столбцом, было бы странно, если бы он не был настроен как первый столбец data.frame из с самого начала. И вы всегда можете изменить порядок столбцов, чтобы сделать это так. Преимущественным следствием этого предположения является то, что имя ключевого столбца не обязательно должно быть жестко закодировано, хотя я предполагаю, что он просто заменяет одно предположение другим. Конкретность - еще одно преимущество целочисленного индексации, а также скорости. В приведенных ниже тестах я изменил реализацию, чтобы использовать индексацию имени строки, чтобы соответствовать конкурирующим реализациям.
Я думаю, что это особенно подходящее решение, если у вас есть несколько таблиц, которые вы хотите оставить, присоединиться к одной большой таблице. Повторное восстановление всей таблицы для каждого слияния было бы ненужным и неэффективным.
С другой стороны, если вам нужно, чтобы joinee оставался неизменным в этой операции по какой-либо причине, то это решение не может быть использовано, так как оно напрямую изменяет joinee. Хотя в этом случае вы могли бы просто сделать копию и выполнить назначение на месте в копии.
В качестве примечания я кратко рассмотрел возможные подходящие решения для многоколоночных ключей. К сожалению, единственные совпадающие решения, которые я нашел, были:
- неэффективные конкатенации. например
match(interaction(df1$a,df1$b),interaction(df2$a,df2$b)), или же идея сpaste(). - неэффективные декартовы конъюнкции, например.
outer(df1$a,df2$a,`==`) & outer(df1$b,df2$b,`==`). - base R
merge()и эквивалентные функции слияния на основе пакетов, которые всегда выделяют новую таблицу для возврата объединенного результата и, следовательно, не подходят для решения на основе места размещения.
Например, см. Согласование нескольких столбцов в разных кадрах данных и получение другого столбца в качестве результата, соответствуют двум столбцам с двумя другие столбцы, Соответствие по нескольким столбцам, и обман этого вопроса, когда я изначально придумал решение на месте, Объедините два кадра данных с различным количеством строк в R.
Бенчмаркинг
Я решил сделать свой собственный бенчмаркинг, чтобы посмотреть, как подход на основе места размещения сравнивается с другими решениями, которые были предложены в этом вопросе.
Код тестирования:
library(microbenchmark);
library(data.table);
library(sqldf);
library(plyr);
library(dplyr);
solSpecs <- list(
merge=list(testFuncs=list(
inner=function(df1,df2,key) merge(df1,df2,key),
left =function(df1,df2,key) merge(df1,df2,key,all.x=T),
right=function(df1,df2,key) merge(df1,df2,key,all.y=T),
full =function(df1,df2,key) merge(df1,df2,key,all=T)
)),
data.table.unkeyed=list(argSpec='data.table.unkeyed',testFuncs=list(
inner=function(dt1,dt2,key) dt1[dt2,on=key,nomatch=0L,allow.cartesian=T],
left =function(dt1,dt2,key) dt2[dt1,on=key,allow.cartesian=T],
right=function(dt1,dt2,key) dt1[dt2,on=key,allow.cartesian=T],
full =function(dt1,dt2,key) merge(dt1,dt2,key,all=T,allow.cartesian=T) ## calls merge.data.table()
)),
data.table.keyed=list(argSpec='data.table.keyed',testFuncs=list(
inner=function(dt1,dt2) dt1[dt2,nomatch=0L,allow.cartesian=T],
left =function(dt1,dt2) dt2[dt1,allow.cartesian=T],
right=function(dt1,dt2) dt1[dt2,allow.cartesian=T],
full =function(dt1,dt2) merge(dt1,dt2,all=T,allow.cartesian=T) ## calls merge.data.table()
)),
sqldf.unindexed=list(testFuncs=list( ## note: must pass connection=NULL to avoid running against the live DB connection, which would result in collisions with the residual tables from the last query upload
inner=function(df1,df2,key) sqldf(paste0('select * from df1 inner join df2 using(',paste(collapse=',',key),')'),connection=NULL),
left =function(df1,df2,key) sqldf(paste0('select * from df1 left join df2 using(',paste(collapse=',',key),')'),connection=NULL),
right=function(df1,df2,key) sqldf(paste0('select * from df2 left join df1 using(',paste(collapse=',',key),')'),connection=NULL) ## can't do right join proper, not yet supported; inverted left join is equivalent
##full =function(df1,df2,key) sqldf(paste0('select * from df1 full join df2 using(',paste(collapse=',',key),')'),connection=NULL) ## can't do full join proper, not yet supported; possible to hack it with a union of left joins, but too unreasonable to include in testing
)),
sqldf.indexed=list(testFuncs=list( ## important: requires an active DB connection with preindexed main.df1 and main.df2 ready to go; arguments are actually ignored
inner=function(df1,df2,key) sqldf(paste0('select * from main.df1 inner join main.df2 using(',paste(collapse=',',key),')')),
left =function(df1,df2,key) sqldf(paste0('select * from main.df1 left join main.df2 using(',paste(collapse=',',key),')')),
right=function(df1,df2,key) sqldf(paste0('select * from main.df2 left join main.df1 using(',paste(collapse=',',key),')')) ## can't do right join proper, not yet supported; inverted left join is equivalent
##full =function(df1,df2,key) sqldf(paste0('select * from main.df1 full join main.df2 using(',paste(collapse=',',key),')')) ## can't do full join proper, not yet supported; possible to hack it with a union of left joins, but too unreasonable to include in testing
)),
plyr=list(testFuncs=list(
inner=function(df1,df2,key) join(df1,df2,key,'inner'),
left =function(df1,df2,key) join(df1,df2,key,'left'),
right=function(df1,df2,key) join(df1,df2,key,'right'),
full =function(df1,df2,key) join(df1,df2,key,'full')
)),
dplyr=list(testFuncs=list(
inner=function(df1,df2,key) inner_join(df1,df2,key),
left =function(df1,df2,key) left_join(df1,df2,key),
right=function(df1,df2,key) right_join(df1,df2,key),
full =function(df1,df2,key) full_join(df1,df2,key)
)),
in.place=list(testFuncs=list(
left =function(df1,df2,key) { cns <- setdiff(names(df2),key); df1[cns] <- df2[match(df1[,key],df2[,key]),cns]; df1; },
right=function(df1,df2,key) { cns <- setdiff(names(df1),key); df2[cns] <- df1[match(df2[,key],df1[,key]),cns]; df2; }
))
);
getSolTypes <- function() names(solSpecs);
getJoinTypes <- function() unique(unlist(lapply(solSpecs,function(x) names(x$testFuncs))));
getArgSpec <- function(argSpecs,key=NULL) if (is.null(key)) argSpecs$default else argSpecs[[key]];
initSqldf <- function() {
sqldf(); ## creates sqlite connection on first run, cleans up and closes existing connection otherwise
if (exists('sqldfInitFlag',envir=globalenv(),inherits=F) && sqldfInitFlag) { ## false only on first run
sqldf(); ## creates a new connection
} else {
assign('sqldfInitFlag',T,envir=globalenv()); ## set to true for the one and only time
}; ## end if
invisible();
}; ## end initSqldf()
setUpBenchmarkCall <- function(argSpecs,joinType,solTypes=getSolTypes(),env=parent.frame()) {
## builds and returns a list of expressions suitable for passing to the list argument of microbenchmark(), and assigns variables to resolve symbol references in those expressions
callExpressions <- list();
nms <- character();
for (solType in solTypes) {
testFunc <- solSpecs[[solType]]$testFuncs[[joinType]];
if (is.null(testFunc)) next; ## this join type is not defined for this solution type
testFuncName <- paste0('tf.',solType);
assign(testFuncName,testFunc,envir=env);
argSpecKey <- solSpecs[[solType]]$argSpec;
argSpec <- getArgSpec(argSpecs,argSpecKey);
argList <- setNames(nm=names(argSpec$args),vector('list',length(argSpec$args)));
for (i in seq_along(argSpec$args)) {
argName <- paste0('tfa.',argSpecKey,i);
assign(argName,argSpec$args[[i]],envir=env);
argList[[i]] <- if (i%in%argSpec$copySpec) call('copy',as.symbol(argName)) else as.symbol(argName);
}; ## end for
callExpressions[[length(callExpressions)+1L]] <- do.call(call,c(list(testFuncName),argList),quote=T);
nms[length(nms)+1L] <- solType;
}; ## end for
names(callExpressions) <- nms;
callExpressions;
}; ## end setUpBenchmarkCall()
harmonize <- function(res) {
res <- as.data.frame(res); ## coerce to data.frame
for (ci in which(sapply(res,is.factor))) res[[ci]] <- as.character(res[[ci]]); ## coerce factor columns to character
for (ci in which(sapply(res,is.logical))) res[[ci]] <- as.integer(res[[ci]]); ## coerce logical columns to integer (works around sqldf quirk of munging logicals to integers)
##for (ci in which(sapply(res,inherits,'POSIXct'))) res[[ci]] <- as.double(res[[ci]]); ## coerce POSIXct columns to double (works around sqldf quirk of losing POSIXct class) ----- POSIXct doesn't work at all in sqldf.indexed
res <- res[order(names(res))]; ## order columns
res <- res[do.call(order,res),]; ## order rows
res;
}; ## end harmonize()
checkIdentical <- function(argSpecs,solTypes=getSolTypes()) {
for (joinType in getJoinTypes()) {
callExpressions <- setUpBenchmarkCall(argSpecs,joinType,solTypes);
if (length(callExpressions)<2L) next;
ex <- harmonize(eval(callExpressions[[1L]]));
for (i in seq(2L,len=length(callExpressions)-1L)) {
y <- harmonize(eval(callExpressions[[i]]));
if (!isTRUE(all.equal(ex,y,check.attributes=F))) {
ex <<- ex;
y <<- y;
solType <- names(callExpressions)[i];
stop(paste0('non-identical: ',solType,' ',joinType,'.'));
}; ## end if
}; ## end for
}; ## end for
invisible();
}; ## end checkIdentical()
testJoinType <- function(argSpecs,joinType,solTypes=getSolTypes(),metric=NULL,times=100L) {
callExpressions <- setUpBenchmarkCall(argSpecs,joinType,solTypes);
bm <- microbenchmark(list=callExpressions,times=times);
if (is.null(metric)) return(bm);
bm <- summary(bm);
res <- setNames(nm=names(callExpressions),bm[[metric]]);
attr(res,'unit') <- attr(bm,'unit');
res;
}; ## end testJoinType()
testAllJoinTypes <- function(argSpecs,solTypes=getSolTypes(),metric=NULL,times=100L) {
joinTypes <- getJoinTypes();
resList <- setNames(nm=joinTypes,lapply(joinTypes,function(joinType) testJoinType(argSpecs,joinType,solTypes,metric,times)));
if (is.null(metric)) return(resList);
units <- unname(unlist(lapply(resList,attr,'unit')));
res <- do.call(data.frame,c(list(join=joinTypes),setNames(nm=solTypes,rep(list(rep(NA_real_,length(joinTypes))),length(solTypes))),list(unit=units,stringsAsFactors=F)));
for (i in seq_along(resList)) res[i,match(names(resList[[i]]),names(res))] <- resList[[i]];
res;
}; ## end testAllJoinTypes()
testGrid <- function(makeArgSpecsFunc,sizes,overlaps,solTypes=getSolTypes(),joinTypes=getJoinTypes(),metric='median',times=100L) {
res <- expand.grid(size=sizes,overlap=overlaps,joinType=joinTypes,stringsAsFactors=F);
res[solTypes] <- NA_real_;
res$unit <- NA_character_;
for (ri in seq_len(nrow(res))) {
size <- res$size[ri];
overlap <- res$overlap[ri];
joinType <- res$joinType[ri];
argSpecs <- makeArgSpecsFunc(size,overlap);
checkIdentical(argSpecs,solTypes);
cur <- testJoinType(argSpecs,joinType,solTypes,metric,times);
res[ri,match(names(cur),names(res))] <- cur;
res$unit[ri] <- attr(cur,'unit');
}; ## end for
res;
}; ## end testGrid()
Здесь приведен пример примера, основанного на OP, который я продемонстрировал ранее:
## OP example, supplemented with a non-matching row in df2
argSpecs <- list(
default=list(copySpec=1:2,args=list(
df1 <- data.frame(CustomerId=1:6,Product=c(rep('Toaster',3L),rep('Radio',3L))),
df2 <- data.frame(CustomerId=c(2L,4L,6L,7L),State=c(rep('Alabama',2L),'Ohio','Texas')),
'CustomerId'
)),
data.table.unkeyed=list(copySpec=1:2,args=list(
as.data.table(df1),
as.data.table(df2),
'CustomerId'
)),
data.table.keyed=list(copySpec=1:2,args=list(
setkey(as.data.table(df1),CustomerId),
setkey(as.data.table(df2),CustomerId)
))
);
## prepare sqldf
initSqldf();
sqldf('create index df1_key on df1(CustomerId);'); ## upload and create an sqlite index on df1
sqldf('create index df2_key on df2(CustomerId);'); ## upload and create an sqlite index on df2
checkIdentical(argSpecs);
testAllJoinTypes(argSpecs,metric='median');
## join merge data.table.unkeyed data.table.keyed sqldf.unindexed sqldf.indexed plyr dplyr in.place unit
## 1 inner 644.259 861.9345 923.516 9157.752 1580.390 959.2250 270.9190 NA microseconds
## 2 left 713.539 888.0205 910.045 8820.334 1529.714 968.4195 270.9185 224.3045 microseconds
## 3 right 1221.804 909.1900 923.944 8930.668 1533.135 1063.7860 269.8495 218.1035 microseconds
## 4 full 1302.203 3107.5380 3184.729 NA NA 1593.6475 270.7055 NA microseconds
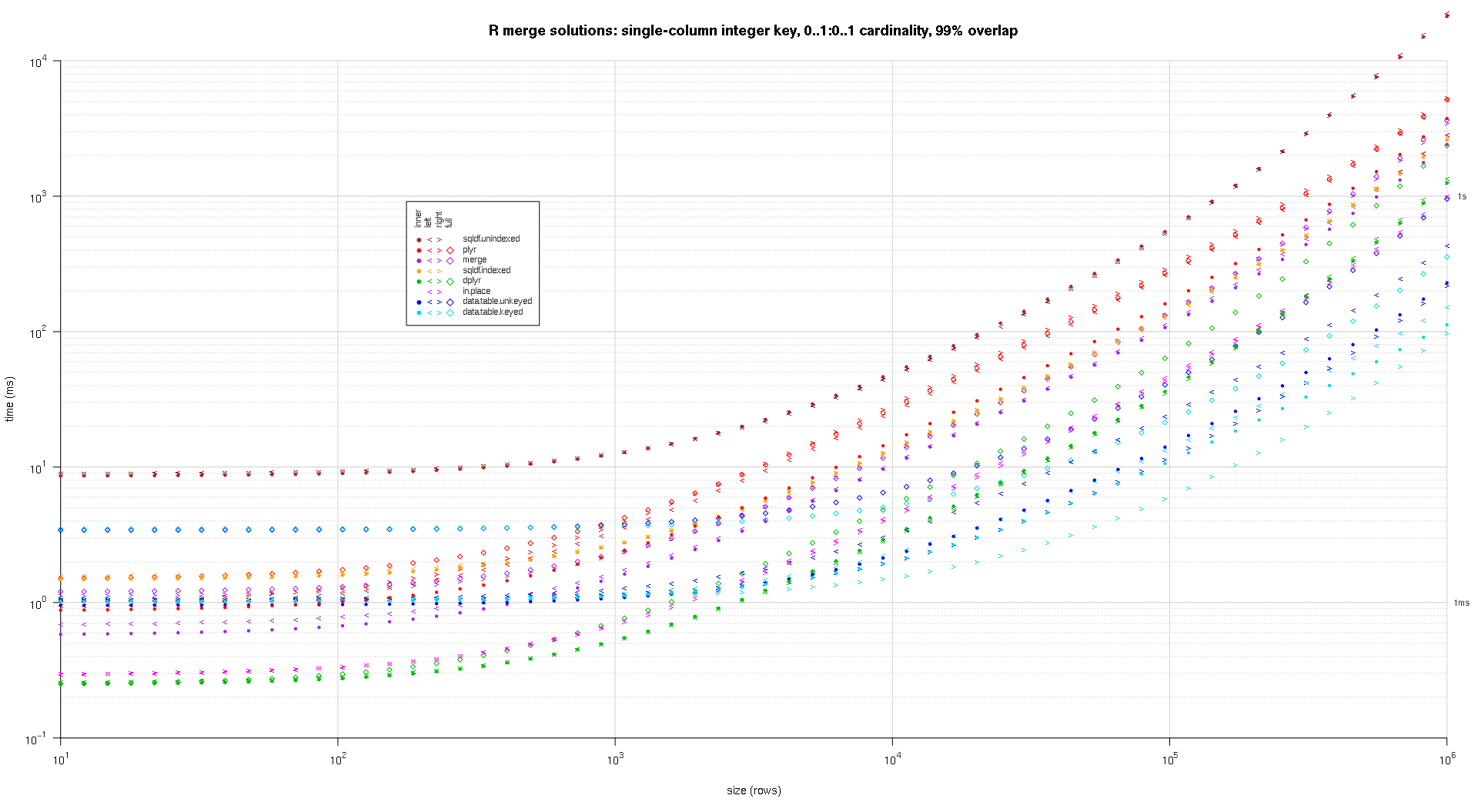
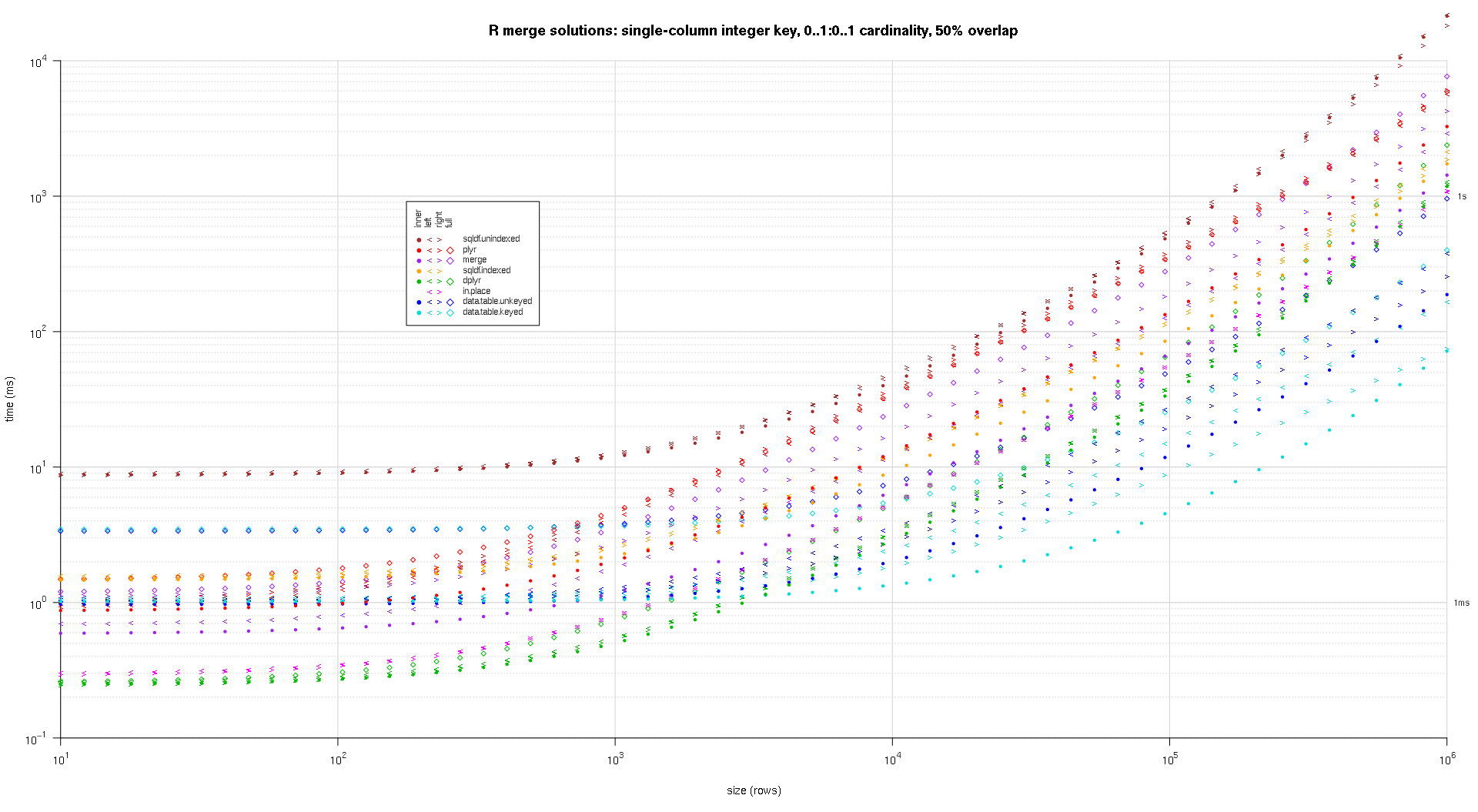
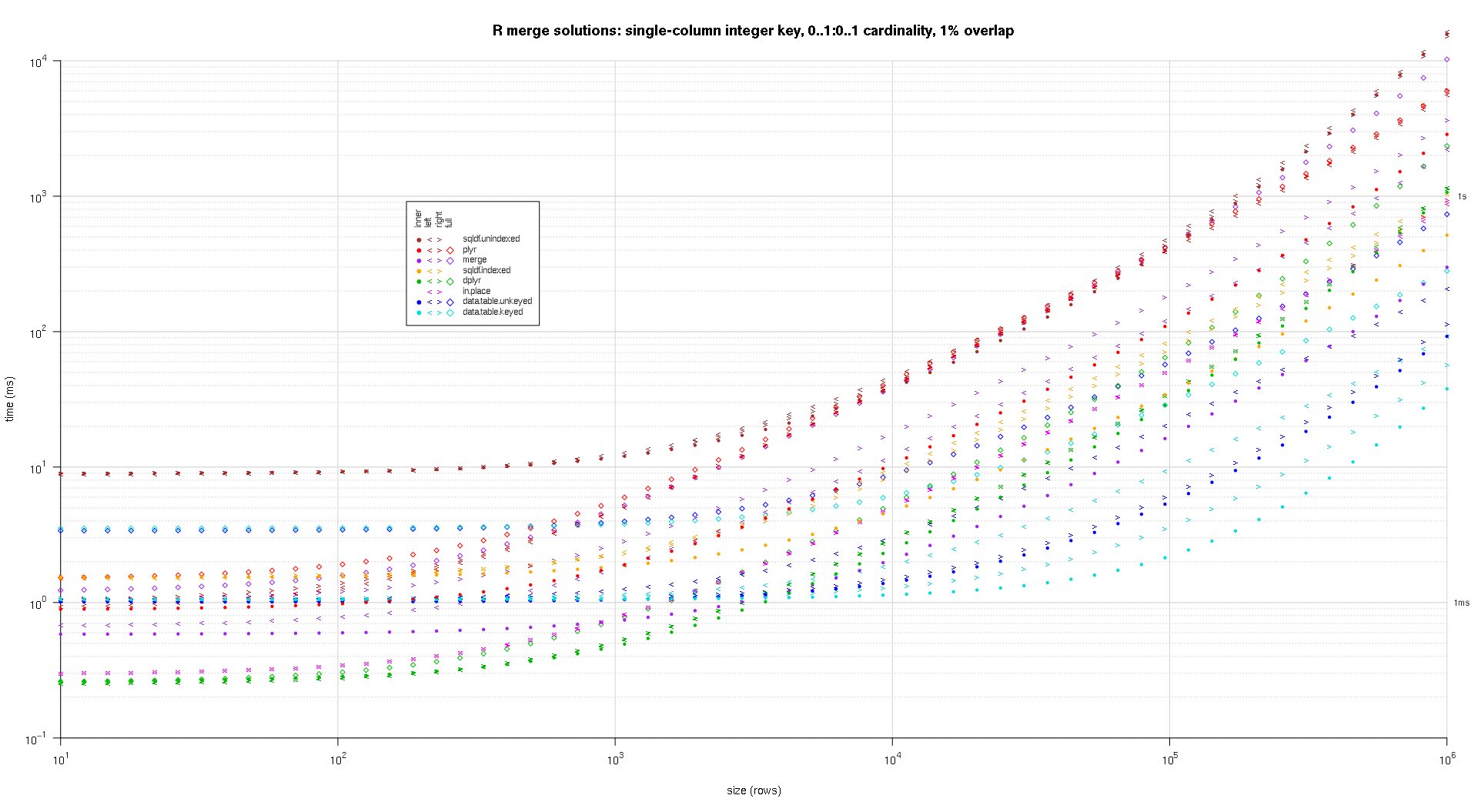
Здесь я сравниваю случайные входные данные, пробуя разные шкалы и различные шаблоны перекрытия клавиш между двумя таблицами ввода. Этот критерий по-прежнему ограничивается случаем целочисленного ключа с одним столбцом. Кроме того, чтобы гарантировать, что решение на месте будет работать как для левого, так и для правого соединения одних и тех же таблиц, во всех случайных тестовых данных используется 0..1:0..1 мощность. Это выполняется путем выборки без замены ключевого столбца первого data.frame при генерации ключевого столбца второго data.frame.
makeArgSpecs.singleIntegerKey.optionalOneToOne <- function(size,overlap) {
com <- as.integer(size*overlap);
argSpecs <- list(
default=list(copySpec=1:2,args=list(
df1 <- data.frame(id=sample(size),y1=rnorm(size),y2=rnorm(size)),
df2 <- data.frame(id=sample(c(if (com>0L) sample(df1$id,com) else integer(),seq(size+1L,len=size-com))),y3=rnorm(size),y4=rnorm(size)),
'id'
)),
data.table.unkeyed=list(copySpec=1:2,args=list(
as.data.table(df1),
as.data.table(df2),
'id'
)),
data.table.keyed=list(copySpec=1:2,args=list(
setkey(as.data.table(df1),id),
setkey(as.data.table(df2),id)
))
);
## prepare sqldf
initSqldf();
sqldf('create index df1_key on df1(id);'); ## upload and create an sqlite index on df1
sqldf('create index df2_key on df2(id);'); ## upload and create an sqlite index on df2
argSpecs;
}; ## end makeArgSpecs.singleIntegerKey.optionalOneToOne()
## cross of various input sizes and key overlaps
sizes <- c(1e1L,1e3L,1e6L);
overlaps <- c(0.99,0.5,0.01);
system.time({ res <- testGrid(makeArgSpecs.singleIntegerKey.optionalOneToOne,sizes,overlaps); });
## user system elapsed
## 22024.65 12308.63 34493.19
Я написал код для создания лог-логарифмов приведенных выше результатов. Я создал отдельный график для каждого процента перекрытия. Это немного загромождено, но мне нравится иметь все типы решений и типы соединений, представленные в одном и том же сюжете.
Я использовал сплайн-интерполяцию, чтобы показать гладкую кривую для каждой комбинации решений/объединения, нарисованной с помощью отдельных символов pch. Тип соединения захватывается символом pch, используя точку для внутренних, левых и правых угловых скобок для левого и правого и алмаза для полного. Тип решения захватывается цветом, как показано в легенде.
plotRes <- function(res,titleFunc,useFloor=F) {
solTypes <- setdiff(names(res),c('size','overlap','joinType','unit')); ## derive from res
normMult <- c(microseconds=1e-3,milliseconds=1); ## normalize to milliseconds
joinTypes <- getJoinTypes();
cols <- c(merge='purple',data.table.unkeyed='blue',data.table.keyed='#00DDDD',sqldf.unindexed='brown',sqldf.indexed='orange',plyr='red',dplyr='#00BB00',in.place='magenta');
pchs <- list(inner=20L,left='<',right='>',full=23L);
cexs <- c(inner=0.7,left=1,right=1,full=0.7);
NP <- 60L;
ord <- order(decreasing=T,colMeans(res[res$size==max(res$size),solTypes],na.rm=T));
ymajors <- data.frame(y=c(1,1e3),label=c('1ms','1s'),stringsAsFactors=F);
for (overlap in unique(res$overlap)) {
x1 <- res[res$overlap==overlap,];
x1[solTypes] <- x1[solTypes]*normMult[x1$unit]; x1$unit <- NULL;
xlim <- c(1e1,max(x1$size));
xticks <- 10^seq(log10(xlim[1L]),log10(xlim[2L]));
ylim <- c(1e-1,10^((if (useFloor) floor else ceiling)(log10(max(x1[solTypes],na.rm=T))))); ## use floor() to zoom in a little more, only sqldf.unindexed will break above, but xpd=NA will keep it visible
yticks <- 10^seq(log10(ylim[1L]),log10(ylim[2L]));
yticks.minor <- rep(yticks[-length(yticks)],each=9L)*1:9;
plot(NA,xlim=xlim,ylim=ylim,xaxs='i',yaxs='i',axes=F,xlab='size (rows)',ylab='time (ms)',log='xy');
abline(v=xticks,col='lightgrey');
abline(h=yticks.minor,col='lightgrey',lty=3L);
abline(h=yticks,col='lightgrey');
axis(1L,xticks,parse(text=sprintf('10^%d',as.integer(log10(xticks)))));
axis(2L,yticks,parse(text=sprintf('10^%d',as.integer(log10(yticks)))),las=1L);
axis(4L,ymajors$y,ymajors$label,las=1L,tick=F,cex.axis=0.7,hadj=0.5);
for (joinType in rev(joinTypes)) { ## reverse to draw full first, since it larger and would be more obtrusive if drawn last
x2 <- x1[x1$joinType==joinType,];
for (solType in solTypes) {
if (any(!is.na(x2[[solType]]))) {
xy <- spline(x2$size,x2[[solType]],xout=10^(seq(log10(x2$size[1L]),log10(x2$size[nrow(x2)]),len=NP)));
points(xy$x,xy$y,pch=pchs[[joinType]],col=cols[solType],cex=cexs[joinType],xpd=NA);
}; ## end if
}; ## end for
}; ## end for
## custom legend
## due to logarithmic skew, must do all distance calcs in inches, and convert to user coords afterward
## the bottom-left corner of the legend will be defined in normalized figure coords, although we can convert to inches immediately
leg.cex <- 0.7;
leg.x.in <- grconvertX(0.275,'nfc','in');
leg.y.in <- grconvertY(0.6,'nfc','in');
leg.x.user <- grconvertX(leg.x.in,'in');
leg.y.user <- grconvertY(leg.y.in,'in');
leg.outpad.w.in <- 0.1;
leg.outpad.h.in <- 0.1;
leg.midpad.w.in <- 0.1;
leg.midpad.h.in <- 0.1;
leg.sol.w.in <- max(strwidth(solTypes,'in',leg.cex));
leg.sol.h.in <- max(strheight(solTypes,'in',leg.cex))*1.5; ## multiplication factor for greater line height
leg.join.w.in <- max(strheight(joinTypes,'in',leg.cex))*1.5; ## ditto
leg.join.h.in <- max(strwidth(joinTypes,'in',leg.cex));
leg.main.w.in <- leg.join.w.in*length(joinTypes);
leg.main.h.in <- leg.sol.h.in*length(solTypes);
leg.x2.user <- grconvertX(leg.x.in+leg.outpad.w.in*2+leg.main.w.in+leg.midpad.w.in+leg.sol.w.in,'in');
leg.y2.user <- grconvertY(leg.y.in+leg.outpad.h.in*2+leg.main.h.in+leg.midpad.h.in+leg.join.h.in,'in');
leg.cols.x.user <- grconvertX(leg.x.in+leg.outpad.w.in+leg.join.w.in*(0.5+seq(0L,length(joinTypes)-1L)),'in');
leg.lines.y.user <- grconvertY(leg.y.in+leg.outpad.h.in+leg.main.h.in-leg.sol.h.in*(0.5+seq(0L,length(solTypes)-1L)),'in');
leg.sol.x.user <- grconvertX(leg.x.in+leg.outpad.w.in+leg.main.w.in+leg.midpad.w.in,'in');
leg.join.y.user <- grconvertY(leg.y.in+leg.outpad.h.in+leg.main.h.in+leg.midpad.h.in,'in');
rect(leg.x.user,leg.y.user,leg.x2.user,leg.y2.user,col='white');
text(leg.sol.x.user,leg.lines.y.user,solTypes[ord],cex=leg.cex,pos=4L,offset=0);
text(leg.cols.x.user,leg.join.y.user,joinTypes,cex=leg.cex,pos=4L,offset=0,srt=90); ## srt rotation applies *after* pos/offset positioning
for (i in seq_along(joinTypes)) {
joinType <- joinTypes[i];
points(rep(leg.cols.x.user[i],length(solTypes)),ifelse(colSums(!is.na(x1[x1$joinType==joinType,solTypes[ord]]))==0L,NA,leg.lines.y.user),pch=pchs[[joinType]],col=cols[solTypes[ord]]);
}; ## end for
title(titleFunc(overlap));
readline(sprintf('overlap %.02f',overlap));
}; ## end for
}; ## end plotRes()
titleFunc <- function(overlap) sprintf('R merge solutions: single-column integer key, 0..1:0..1 cardinality, %d%% overlap',as.integer(overlap*100));
plotRes(res,titleFunc,T);
Вот второй крупномасштабный тест, который более тяжелый, по отношению к количеству и типам ключевых столбцов, а также к мощности. Для этого теста я использую три ключевых столбца: один символ, одно целое и одно логическое, без ограничений на мощность (т.е. 0..*:0..*). (В общем случае нецелесообразно определять ключевые столбцы с двойными или сложными значениями из-за осложнений сравнения с плавающей запятой, и в основном никто никогда не использует тип raw, а тем более для ключевых столбцов, поэтому я не включил эти типы в ключ столбцы. Кроме того, для информации я первоначально попытался использовать четыре ключевых столбца, включив в него столбец POSIXct, но тип POSIXct по какой-то причине плохо играл с решением sqldf.indexed, возможно, из-за аномалий сравнения с плавающей запятой, поэтому я удалил его.)
makeArgSpecs.assortedKey.optionalManyToMany <- function(size,overlap,uniquePct=75) {
## number of unique keys in df1
u1Size <- as.integer(size*uniquePct/100);
## (roughly) divide u1Size into bases, so we can use expand.grid() to produce the required number of unique key values with repetitions within individual key columns
## use ceiling() to ensure we cover u1Size; will truncate afterward
u1SizePerKeyColumn <- as.integer(ceiling(u1Size^(1/3)));
## generate the unique key values for df1
keys1 <- expand.grid(stringsAsFactors=F,
idCharacter=replicate(u1SizePerKeyColumn,paste(collapse='',sample(letters,sample(4:12,1L),T))),
idInteger=sample(u1SizePerKeyColumn),
idLogical=sample(c(F,T),u1SizePerKeyColumn,T)
##idPOSIXct=as.POSIXct('2016-01-01 00:00:00','UTC')+sample(u1SizePerKeyColumn)
)[seq_len(u1Size),];
## rbind some repetitions of the unique keys; this will prepare one side of the many-to-many relationship
## also scramble the order afterward
keys1 <- rbind(keys1,keys1[sample(nrow(keys1),size-u1Size,T),])[sample(size),];
## common and unilateral key counts
com <- as.integer(size*overlap);
uni <- size-com;
## generate some unilateral keys for df2 by synthesizing outside of the idInteger range of df1
keys2 <- data.frame(stringsAsFactors=F,
idCharacter=replicate(uni,paste(collapse='',sample(letters,sample(4:12,1L),T))),
idInteger=u1SizePerKeyColumn+sample(uni),
idLogical=sample(c(F,T),uni,T)
##idPOSIXct=as.POSIXct('2016-01-01 00:00:00','UTC')+u1SizePerKeyColumn+sample(uni)
);
## rbind random keys from df1; this will complete the many-to-many relationship
## also scramble the order afterward
keys2 <- rbind(keys2,keys1[sample(nrow(keys1),com,T),])[sample(size),];
##keyNames <- c('idCharacter','idInteger','idLogical','idPOSIXct');
keyNames <- c('idCharacter','idInteger','idLogical');
## note: was going to use raw and complex type for two of the non-key columns, but data.table doesn't seem to fully support them
argSpecs <- list(
default=list(copySpec=1:2,args=list(
df1 <- cbind(stringsAsFactors=F,keys1,y1=sample(c(F,T),size,T),y2=sample(size),y3=rnorm(size),y4=replicate(size,paste(collapse='',sample(letters,sample(4:12,1L),T)))),
df2 <- cbind(stringsAsFactors=F,keys2,y5=sample(c(F,T),size,T),y6=sample(size),y7=rnorm(size),y8=replicate(size,paste(collapse='',sample(letters,sample(4:12,1L),T)))),
keyNames
)),
data.table.unkeyed=list(copySpec=1:2,args=list(
as.data.table(df1),
as.data.table(df2),
keyNames
)),
data.table.keyed=list(copySpec=1:2,args=list(
setkeyv(as.data.table(df1),keyNames),
setkeyv(as.data.table(df2),keyNames)
))
);
## prepare sqldf
initSqldf();
sqldf(paste0('create index df1_key on df1(',paste(collapse=',',keyNames),');')); ## upload and create an sqlite index on df1
sqldf(paste0('create index df2_key on df2(',paste(collapse=',',keyNames),');')); ## upload and create an sqlite index on df2
argSpecs;
}; ## end makeArgSpecs.assortedKey.optionalManyToMany()
sizes <- c(1e1L,1e3L,1e5L); ## 1e5L instead of 1e6L to respect more heavy-duty inputs
overlaps <- c(0.99,0.5,0.01);
solTypes <- setdiff(getSolTypes(),'in.place');
system.time({ res <- testGrid(makeArgSpecs.assortedKey.optionalManyToMany,sizes,overlaps,solTypes); });
## user system elapsed
## 38895.50 784.19 39745.53
Полученные графики, используя один и тот же код построения, приведенный выше:
titleFunc <- function(overlap) sprintf('R merge solutions: character/integer/logical key, 0..*:0..* cardinality, %d%% overlap',as.integer(overlap*100));
plotRes(res,titleFunc,F);
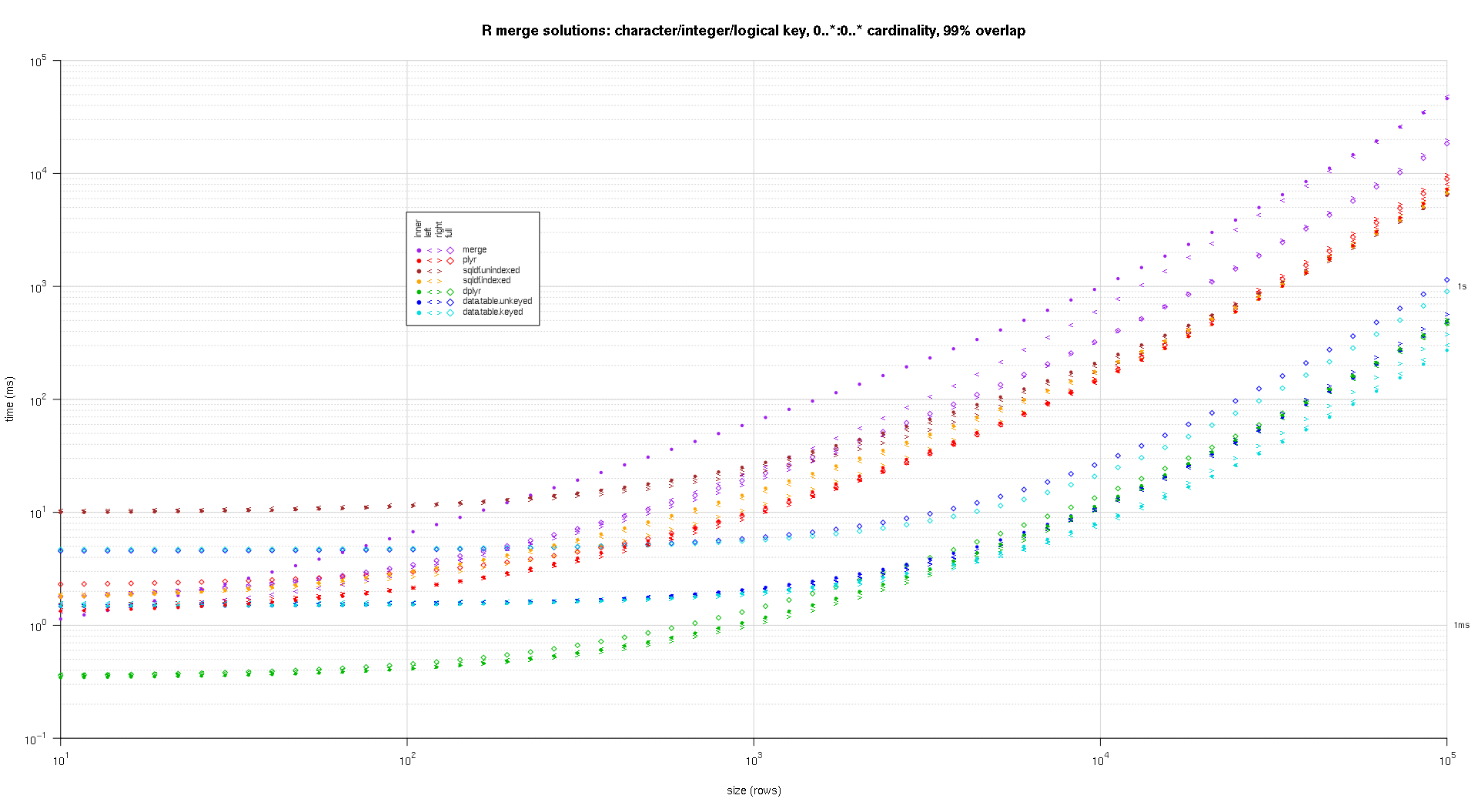
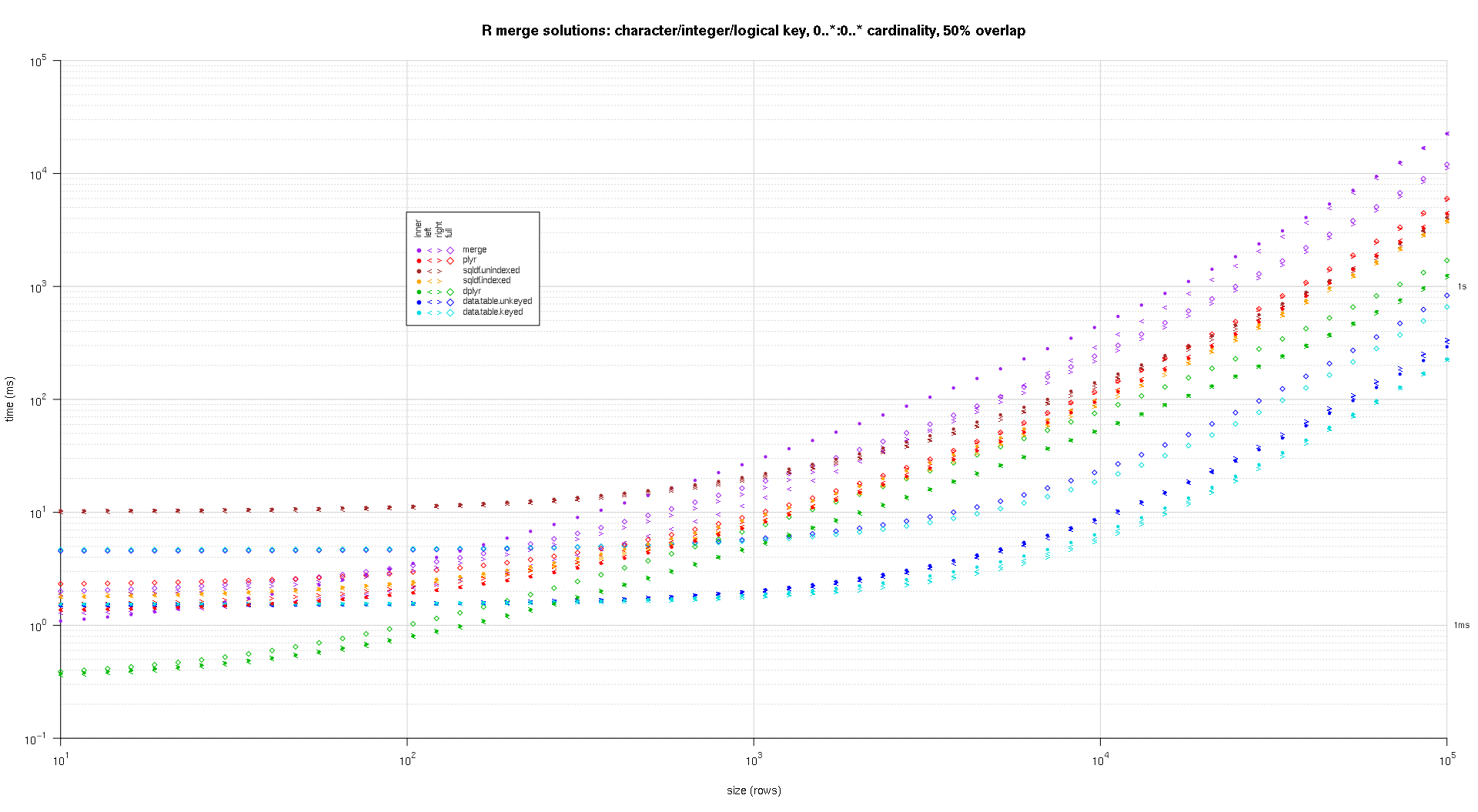
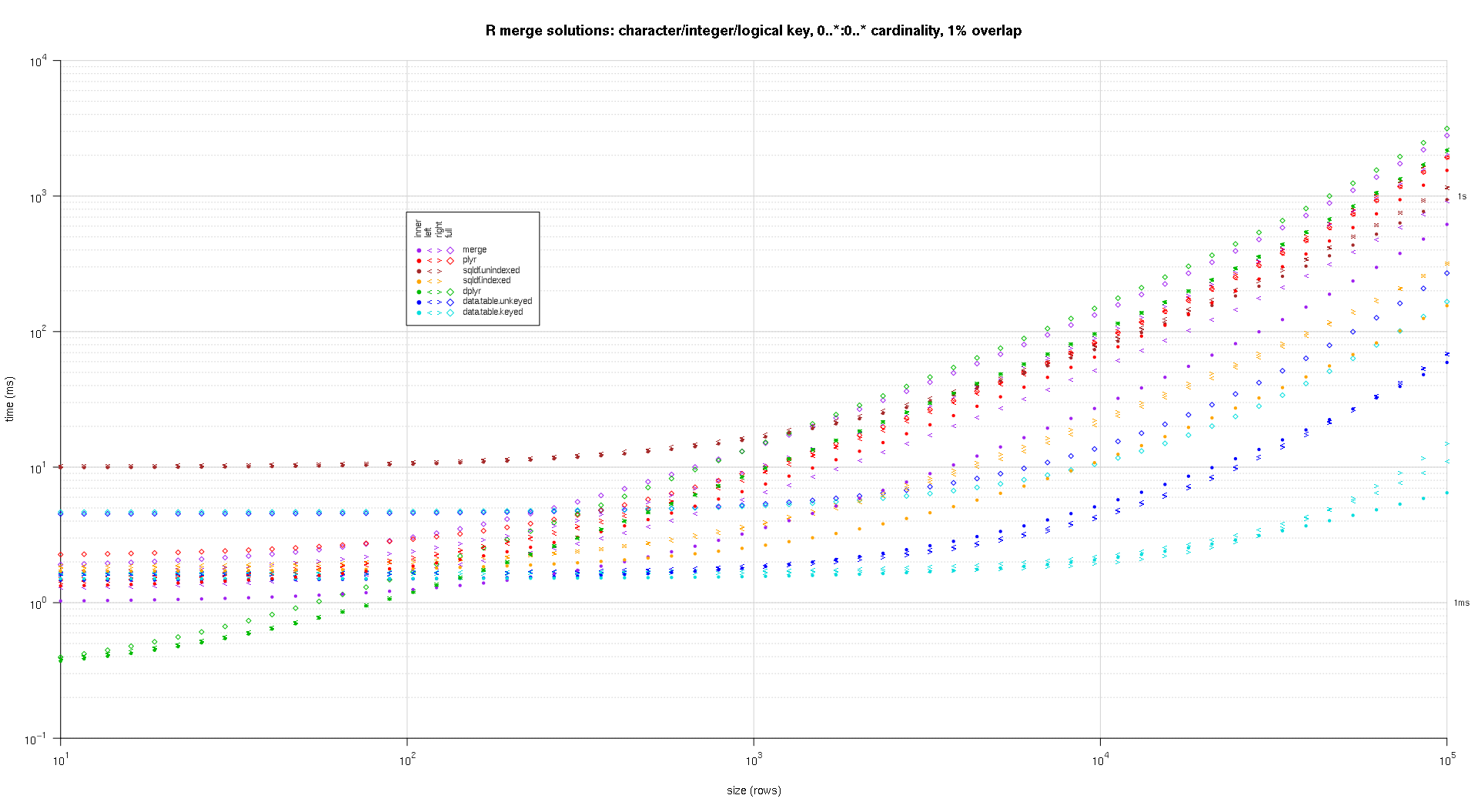
-
0очень хороший анализ, но жаль, что вы установили масштаб от 10 ^ 1 до 10 ^ 6, это настолько крошечные наборы, что разница в скорости практически не имеет значения. 10 ^ 6 до 10 ^ 8 было бы интересно посмотреть!
-
0Я также заметил, что вы включили время приведения класса в бенчмарк, что делает его недействительным для операции соединения.
Для внутреннего соединения во всех столбцах вы также можете использовать fintersect из data.table-package или intersect из dplyr-пакета в качестве альтернативы merge без указания by -колонков. это даст строки, которые равны между двумя кадрами данных:
merge(df1, df2)
# V1 V2
# 1 B 2
# 2 C 3
dplyr::intersect(df1, df2)
# V1 V2
# 1 B 2
# 2 C 3
data.table::fintersect(setDT(df1), setDT(df2))
# V1 V2
# 1: B 2
# 2: C 3
Пример данных:
df1 <- data.frame(V1 = LETTERS[1:4], V2 = 1:4)
df2 <- data.frame(V1 = LETTERS[2:3], V2 = 2:3)
- Используя функцию
merge, мы можем выбрать переменную левой таблицы или правой таблицы, так же, как все мы знакомы с оператором select в SQL (EX: Выберите a. *... или Select b. * from.....) -
Мы должны добавить дополнительный код, который будет подмножаться из недавно объединенной таблицы.
-
SQL: -
select a.* from df1 a inner join df2 b on a.CustomerId=b.CustomerId -
R: -
merge(df1, df2, by.x = "CustomerId", by.y = "CustomerId")[,names(df1)]
-
То же самое
-
SQL: -
select b.* from df1 a inner join df2 b on a.CustomerId=b.CustomerId -
R: -
merge(df1, df2, by.x = "CustomerId", by.y = "CustomerId")[,names(df2)]
Обновить соединение. Еще одним важным соединением в стиле SQL является " соединение для обновления ", где столбцы в одной таблице обновляются (или создаются) с использованием другой таблицы.
Изменение таблиц примеров OP...
sales = data.frame(
CustomerId = c(1, 1, 1, 3, 4, 6),
Year = 2000:2005,
Product = c(rep("Toaster", 3), rep("Radio", 3))
)
cust = data.frame(
CustomerId = c(1, 1, 4, 6),
Year = c(2001L, 2002L, 2002L, 2002L),
State = state.name[1:4]
)
sales
# CustomerId Year Product
# 1 2000 Toaster
# 1 2001 Toaster
# 1 2002 Toaster
# 3 2003 Radio
# 4 2004 Radio
# 6 2005 Radio
cust
# CustomerId Year State
# 1 2001 Alabama
# 1 2002 Alaska
# 4 2002 Arizona
# 6 2002 Arkansas
Предположим, мы хотим добавить состояние клиента из cust в таблицу покупок, sales, игнорируя столбец года. С базой R мы можем идентифицировать совпадающие строки и затем скопировать значения:
sales$State <- cust$State[ match(sales$CustomerId, cust$CustomerId) ]
# CustomerId Year Product State
# 1 2000 Toaster Alabama
# 1 2001 Toaster Alabama
# 1 2002 Toaster Alabama
# 3 2003 Radio <NA>
# 4 2004 Radio Arizona
# 6 2005 Radio Arkansas
# cleanup for the next example
sales$State <- NULL
Как можно видеть здесь, match выбирает первую соответствующую строку из таблицы клиентов.
Обновить соединение с несколькими столбцами. Подход выше хорошо работает, когда мы присоединяемся только к одному столбцу и удовлетворены первым совпадением. Предположим, мы хотим, чтобы год измерения в таблице клиентов соответствовал году продажи.
Как упоминает @bgoldst ответ, match со interaction может быть вариантом для этого случая. Более просто, можно использовать data.table:
library(data.table)
setDT(sales); setDT(cust)
sales[, State := cust[sales, on=.(CustomerId, Year), x.State]]
# CustomerId Year Product State
# 1: 1 2000 Toaster <NA>
# 2: 1 2001 Toaster Alabama
# 3: 1 2002 Toaster Alaska
# 4: 3 2003 Radio <NA>
# 5: 4 2004 Radio <NA>
# 6: 6 2005 Radio <NA>
# cleanup for next example
sales[, State := NULL]
Сопровождение обновления объединяется. В качестве альтернативы, мы можем захотеть принять последнее состояние, в котором был найден клиент:
sales[, State := cust[sales, on=.(CustomerId, Year), roll=TRUE, x.State]]
# CustomerId Year Product State
# 1: 1 2000 Toaster <NA>
# 2: 1 2001 Toaster Alabama
# 3: 1 2002 Toaster Alaska
# 4: 3 2003 Radio <NA>
# 5: 4 2004 Radio Arizona
# 6: 6 2005 Radio Arkansas
Три примера выше всего сосредоточены на создании/добавлении нового столбца. См. Соответствующий R FAQ для примера обновления/изменения существующего столбца.
Ещё вопросы
- 0Вызов функции из директивы без изолированной области видимости
- 1Один массив равен другому. Как заморозить одно при смене другого?
- 0Создать синтаксическую ошибку триггера при вставке триггера
- 1Магистральная Марионетка не стреляет маршрутами
- 1Android SetPixels () Объяснение и пример?
- 1Linq to sql Отличное после присоединения
- 0Python утилизация данных с неправильной HTML-структурой
- 1Как добиться старого появления сообщения об ошибке в дизайне материала TextInputLayout? [Дубликат]
- 1Как поделиться кодом котлина в IntelliJ IDEA между рабочим столом, android и сервером?
- 0Как обновить страницу и добавить параметр URL?
- 1не удается скрыть бар Лебель на временной шкале Google
- 1Строковый параметр слишком длинный. извлечение данных из базы данных в шаблон слова
- 0Если в iframe показать / скрыть div
- 3Рассчитать остаточное отклонение от модели логистической регрессии scikit-learn
- 0Связь между потоками OpenMP
- 0Директива общего доступа между приложениями в AngularJS
- 0Использование Jquery для поиска текста, содержащего скобки
- 1что означает и использует оператор -> в граалях?
- 1Android 8: невозможно изменить режим звонка на бесшумный, когда режим звонка беззвучный
- 0Как загрузить AJAX файл без ошибок?
- 0MSQL DDL от JDL - Jhipster
- 0Ошибки проверки разметки W3C
- 1Проблемы новичка с Eclipse и запуска импортированного файла .jar?
- 0заставить код jquery работать для динамически добавляемого контента
- 0динамическое добавление строки в таблицу не работает с помощью jquery
- 1ReaderWriterLock.UpgradeToWriterLock не генерирует исключение по истечении времени ожидания?
- 1Получить данные JSON после их сохранения в переменной
- 0Есть ли простой способ найти последнюю дату дня недели в текущем месяце?
- 0массивы javascript внутри массива
- 0Игра встряхивания мыши Javascript не работает должным образом
- 0проверка формы зависит от другого поля
- 1Regex не работает
- 0Назначение аргументов командной строки для функций
- 1Отправка электронной почты в формате HTML со встроенным изображением с помощью JavaMail - медленная загрузка изображения?
- 0центрированный, но также фиксированный
- 1Разделить или объединить действия по дате
- 1C # объект или массив
- 0PHP не удалось загрузить папку поставщика: как установить composer на мой сервер?
- 1Использование понимания вложенного списка для проверки и изменения всех столбцов фрейма данных
- 0отправка почты с использованием бесплатной функции codignator, доставляемой как спам
- 0Скопируйте вывод qDebug ()
- 1Javascript извлечь регулярное выражение из строки
- 0Получите запись не более 7 дней с момента публикации
- 1Как использовать Содержит с Guid?
- 1Обнаружение сенсорного флажка
- 0Необходимо найти МАКСИМАЛЬНОЕ значение между двумя датами аукциона
- 1Дата в UTC зоне на Java с использованием Joda-Time
- 0Сохраните данные JSON в текстовый файл и прочитайте его
- 0угловая директива была вызвана только один раз
- 1Windows Phone - привязка TextBox или другого элемента управления к параметру CommandParameter кнопки
