Инструменты для изготовления латексных столов в R
По общему запросу, wiki сообщества по созданию латексных таблиц в R. В этом посте я расскажу о наиболее часто используемых пакетах и блогах с кодом для создания латексных таблиц из менее простых объектов. Пожалуйста, не стесняйтесь добавлять какие-либо пропущенные и/или давать советы, подсказки и небольшие трюки о том, как создавать красиво отформатированные латексные таблицы с R.
Пакеты:
- xtable: для стандартных таблиц большинства простых объектов. Хорошую галерею с примерами можно найти здесь.
- memisc: инструмент для управления данными опроса, содержит некоторые инструменты для латексных таблиц оценок базовой модели регрессии.
- Hmisc содержит функцию
latex(), которая создает файл tex, содержащий выбранный объект. Он довольно гибкий и может также выводить таблицыlongtableлатекса. Там много информации в файле справки?latex - miscFuncs имеет опрятную функцию "latextable", которая преобразует матричные данные со смешанными алфавитными и числовыми элементами в таблицу LaTeX и печатает их на консоли, чтобы их можно было скопировать и вставить в документ LaTeX.
- texreg package (JSS paper) преобразует вывода статистической модели в таблицы LaTeX. Объединяет несколько моделей. Может справиться с примерно 50 различными типами моделей, включая сетевые модели и многоуровневые модели (lme и lme4).
- reporttools package (JSS paper) является другой вариант для описательной статистики о непрерывных, категориальных и переменных даты.
- tables - это, пожалуй, самый общий пакет для создания таблицы LaTeX в R для описательной статистики.
- stargazer пакет делает хорошие сравнительные статистические статистические таблицы
Блоги и фрагменты кода
- Существует функция outreg Paul Johnson, которая дает Stata-подобные таблицы в Latex для вывода регрессий. Это отлично работает.
- Как указано в более раннем вопросе, есть фрагмент кода для адаптировать пакет memisc для объектов lme4.
Похожие вопросы:
- Предложение для пакета создания таблицы R/LaTeX
- Выходной пакет качества Rreport/LaTeX
- сортировка таблицы для выхода латекса с помощью xtable
- Любой способ создать таблицу LaTeX из подходящего объекта модели lme4 mer?
- R data.frame со сложными указанными заголовками для выхода латекса с xtable
- Автоматическое добавление таблиц быстро к латексу из R с очень гибким и интересным синтаксисом с использованием языка формул
-
4Что касается перекрестной проверки (stats.SE), следующий пост в блоге будет интересен читателям здесь: Некоторые заметки о создании эффективных таблиц .gung
-
2Вы также можете использовать ztable. Это позволяет легко создавать таблицы с полосками зебры в форматах LaTeX и HTML. Это довольно гибко и просто: cran.r-project.org/web/packages/ztable/vignettes/ztable.htmlskan
8 ответов
Я хотел бы добавить упоминание пакета "brew". Вы можете написать файл шаблона brew, который будет LaTeX с заполнителями, а затем "brew", чтобы создать .tex файл для \include или\input в ваш LaTeX. Что-то вроде:
\begin{tabular}{l l}
A & <%= fit$A %> \\
B & <%= fit$B %> \\
\end{tabular}
Синтаксис brew также может обрабатывать циклы, поэтому вы можете создать строку таблицы для каждой строки фрейма данных.
-
0Пакет R.rsp и его функция rstring () аналогичны brew :: brew (). Не уверен, что это лучше, но в пакете, конечно, больше вещей. В любом случае мне нравится этот подход, так как он дает большую гибкость в коде tex, не жертвуя воспроизводимостью.
Пакет stargazer - еще один хороший вариант. Он поддерживает объекты из многих часто используемых функций и пакетов (lm, glm, svyreg, survival, pscl, AER), а также от zelig. В дополнение к регрессионным таблицам он также может выводить сводную статистику для фреймов данных или напрямую выводить содержимое фреймов данных.
Спасибо Джорису за создание этого вопроса. Надеюсь, что это будет сделано в вики сообщества.
Пакеты booktabs в латексе создают красивые таблицы. Вот сообщение в блоге о том, как использовать xtable для создавать латексные таблицы, которые используют booktabs
Я бы также добавил пакет apsrtable в микс, поскольку он создает красиво выглядящие таблицы регрессии.
Другая идея. Некоторые из этих пакетов (например, memisc и apsrtable) позволяют легко расширять код для создания таблиц для разных объектов регрессии. Одним из таких примеров является код lme4 memisc, показанный в вопросе. Возможно, было бы целесообразно запустить репозиторий github для сбора таких фрагментов кода, и со временем может даже добавить его в пакет memisc. Любые участники?
У меня есть несколько трюков и работы вокруг интересных "функций" xtable и Latex, которые я расскажу здесь.
Trick # 1: Удаление дубликатов в столбцах и трюке # 2: Использование Booktabs
Сначала загрузите пакеты и определите мою чистую функцию
<<label=first, include=FALSE, echo=FALSE>>=
library(xtable)
library(plyr)
cleanf <- function(x){
oldx <- c(FALSE, x[-1]==x[-length(x)])
# is the value equal to the previous?
res <- x
res[oldx] <- NA
return(res)}
Теперь создайте некоторые поддельные данные
data<-data.frame(animal=sample(c("elephant", "dog", "cat", "fish", "snake"), 100,replace=TRUE),
colour=sample(c("red", "blue", "green", "yellow"), 100,replace=TRUE),
size=rnorm(100,mean=500, sd=150),
age=rlnorm(100, meanlog=3, sdlog=0.5))
#generate a table
datatable<-ddply(data, .(animal, colour), function(df) {
return(data.frame(size=mean(df$size), age=mean(df$age)))
})
Теперь мы можем создать таблицу и использовать чистую функцию для удаления повторяющихся записей в столбцах меток.
cleandata<-datatable
cleandata$animal<-cleanf(cleandata$animal)
cleandata$colour<-cleanf(cleandata$colour)
@
это нормальный xtable
<<label=normal, results=tex, echo=FALSE>>=
print(
xtable(
datatable
),
tabular.environment='longtable',
latex.environments=c("center"),
floating=FALSE,
include.rownames=FALSE
)
@
это нормальный xxtable, где пользовательская функция превратила дубликаты в NA
<<label=cleandata, results=tex, echo=FALSE>>=
print(
xtable(
cleandata
),
tabular.environment='longtable',
latex.environments=c("center"),
floating=FALSE,
include.rownames=FALSE
)
@
В этой таблице используется пакет booktab (и в заголовках требуется \usepackage {booktabs})
\begin{table}[!h]
\centering
\caption{table using booktabs.}
\label{tab:mytable}
<<label=booktabs, echo=F,results=tex>>=
mat <- xtable(cleandata,digits=rep(2,ncol(cleandata)+1))
foo<-0:(length(mat$animal))
bar<-foo[!is.na(mat$animal)]
print(mat,
sanitize.text.function = function(x){x},
floating=FALSE,
include.rownames=FALSE,
hline.after=NULL,
add.to.row=list(pos=list(-1,bar,nrow(mat)),
command=c("\\toprule ", "\\midrule ", "\\bottomrule ")))
#could extend this with \cmidrule to have a partial line over
#a sub category column and \addlinespace to add space before a total row
@
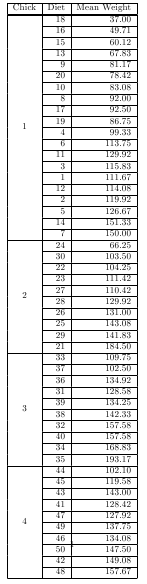
Две утилиты в пакете taRifx могут использоваться совместно для создания многострочных таблиц вложенных иерархий.
library(datasets)
library(taRifx)
library(xtable)
test.by <- bytable(ChickWeight$weight, list( ChickWeight$Chick, ChickWeight$Diet) )
colnames(test.by) <- c('Diet','Chick','Mean Weight')
print(latex.table.by(test.by), include.rownames = FALSE, include.colnames = TRUE, sanitize.text.function = force)
# then add \usepackage{multirow} to the preamble of your LaTeX document
# for longtable support, add ,tabular.environment='longtable' to the print command (plus add in ,floating=FALSE), then \usepackage{longtable} to the LaTeX preamble
-
2Есть ли способ сделать аналогичную вещь, но с целым фреймом данных вместо одного вектора, который вводится с помощью bytable ()?
Еще один пакет R для объединения нескольких моделей регрессии в таблицы LaTeX texreg.
Вы также можете использовать латентную функцию из пакета R micsFuncs:
http://cran.r-project.org/web/packages/miscFuncs/index.html
latextable (M), где M - матрица со смешанными алфавитными и числовыми записями, выводит на экран базовую таблицу LaTeX, которую можно скопировать и вставить в документ LaTeX. Там, где есть небольшие числа, он также заменяет их на индексные обозначения (например, 1.2x10 ^ {- 3}).
... и Trick # 3 Многострочные записи в Xtable
Создайте еще несколько данных
moredata<-data.frame(Nominal=c(1:5), n=rep(5,5),
MeanLinBias=signif(rnorm(5, mean=0, sd=10), digits=4),
LinCI=paste("(",signif(rnorm(5,mean=-2, sd=5), digits=4),
", ", signif(rnorm(5, mean=2, sd=5), digits=4),")",sep=""),
MeanQuadBias=signif(rnorm(5, mean=0, sd=10), digits=4),
QuadCI=paste("(",signif(rnorm(5,mean=-2, sd=5), digits=4),
", ", signif(rnorm(5, mean=2, sd=5), digits=4),")",sep=""))
names(moredata)<-c("Nominal", "n","Linear Model \nBias","Linear \nCI", "Quadratic Model \nBias", "Quadratic \nCI")
Теперь создайте наш xtable, используя функцию sanitize, чтобы заменить имена столбцов правильными командами новой строки Latex (включая двойные обратные косые черты, чтобы R был счастлив)
<<label=multilinetable, results=tex, echo=FALSE>>=
foo<-xtable(moredata)
align(foo) <- c( rep('c',3),'p{1.8in}','p{2in}','p{1.8in}','p{2in}' )
print(foo,
floating=FALSE,
include.rownames=FALSE,
sanitize.text.function = function(str) {
str<-gsub("\n","\\\\", str, fixed=TRUE)
return(str)
},
sanitize.colnames.function = function(str) {
str<-c("Nominal", "n","\\centering Linear Model\\\\ \\% Bias","\\centering Linear \\\\ 95\\%CI", "\\centering Quadratic Model\\\\ \\%Bias", "\\centering Quadratic \\\\ 95\\%CI \\tabularnewline")
return(str)
})
@
(хотя это не идеально, так как нам нужно \tabularnewline, чтобы таблица была отформатирована правильно, а Xtable по-прежнему помещается в final \, поэтому в итоге мы получаем пустую строку под заголовком таблицы.)
Ещё вопросы
- 1Ошибка, когда прямоугольная область интереса выходит за границы - opencv
- 0Как отключить прямой URL-адрес, если он не связан с другой страницей?
- 0Как настроить сервер Go на совместимость с AngularJS html5mode?
- 1Установить данные логической заливки в RecyclerView
- 0Как передать данные JSON из контроллера C # в угловой JS?
- 1Flask bcrypt.check_password_hash () всегда возвращает False, не может сузить мою ошибку
- 1Как найти значения Min и Max для строк в словаре при использовании DictReader в Python 3
- 0Кто-нибудь сталкивался с какими-либо проблемами при использовании jQuery.getJSON () со строкой запроса URL-адреса API PetFinder?
- 0переключать отображение тега p в зависимости от значения внутри
- 0Массив ошибок используется как инициализатор, и я не знаю ошибку
- 0Angularjs: элементы массива Sum для диаграмм
- 1Нормально ли передавать контекст множеству методов?
- 1C # заблокирован функционирует как механизм блокировки?
- 0Объединить два массива, если одно из значений равно ключу
- 0Php dbase возвращает неверное количество столбцов
- 0Запрос привязки данных с повторными значениями на CodeIgniter
- 1Airflow / Composer - шаблон не найден в пакете DAG на молнии
- 1Объект является нулевым, так как второй вызов метода
- 0Как мне создать тесты для библиотеки, которую я создаю в C ++?
- 0Ошибка при использовании STXXL Autogrow
- 0Неверное выражение пути. Должно быть StateFieldPathExpression
- 0Создайте объект JSON динамически Angular
- 0объединить 2 sql запрос местоположения и средний рейтинг
- 0jQuery .on () и .not ()
- 1MediaPlayer проблема с Android
- 1Как я могу обрабатывать изображения с OpenCV параллельно, используя многопроцессорность?
- 0Разрешить регулярное выражение с обратной косой чертой
- 0Получить чистое значение числа Mysql, поданного на основе значения другого поля в той же таблице
- 1Вывод процесса трубопровода в новый процесс
- 1JAXB: Вы должны указать каждое поле, которое будет включено?
- 1Импорт телефонных номеров с облачным питоном Google Python
- 0Объединение информации в одной таблице и перемещение ее в другую в MySQL
- 1Как удалить конкретное значение из списка массивов, а также его следующие два значения на основе одного условия, используя итератор над массивом?
- 1Когда возникает исключение java.io.IOException: сброс соединения с помощью однорангового узла, генерируемого Netty?
- 0Как написать запрос для сопоставления по всем таблицам?
- 1Генерация круговой диаграммы
- 0Ошибка с командой импорта Sqoop
- 1Как правильно перевести метки Kmeans в метки категорий
- 1Entity Framework с динамическим Linq
- 1Гистограмма путем группировки значений в Python
- 0Как настроить работу cron Magento (1.8.1) в Cpanel
- 0ngSwitch не обновляется при изменении модели данных
- 1Боке: Не удается обновить формат всплывающей подсказки
- 0Как получить значения из базы данных для отображения в раскрывающемся списке?
- 0Почему SetInterval не работает (работает только один раз)
- 1Javascript: Как получить значение переменной из конкретного файла из 2 разных файлов?
- 1Создать «курсор» в середине слова
- 1Java JComboBox внешний вид
- 0как отсортировать этот массив в php
- 1Моя программа зачетных книжек не печатает должным образом, чтобы превзойти документ
