Построение двух переменных в виде линий с использованием ggplot2 на одном графике
Очень новичок, но скажу, что у меня есть такие данные:
test_data <-
data.frame(
var0 = 100 + c(0, cumsum(runif(49, -20, 20))),
var1 = 150 + c(0, cumsum(runif(49, -10, 10))),
date = seq(as.Date("2002-01-01"), by="1 month", length.out=100)
)
Как я могу построить как временные ряды var0, так и var1 на одном и том же графике, с date на оси x, используя ggplot2? Бонусные очки, если вы делаете var0 и var1 разные цвета и можете включать легенду!
Я уверен, что это очень просто, но я не могу найти никаких примеров.
5 ответов
Для небольшого количества переменных вы можете построить график вручную:
ggplot(test_data, aes(date)) +
geom_line(aes(y = var0, colour = "var0")) +
geom_line(aes(y = var1, colour = "var1"))
Общий подход состоит в том, чтобы преобразовать данные в длинный формат (используя melt() из пакета reshape или reshape2) или gather() из пакета tidyr:
library("reshape2")
library("ggplot2")
test_data_long <- melt(test_data, id="date") # convert to long format
ggplot(data=test_data_long,
aes(x=date, y=value, colour=variable)) +
geom_line()
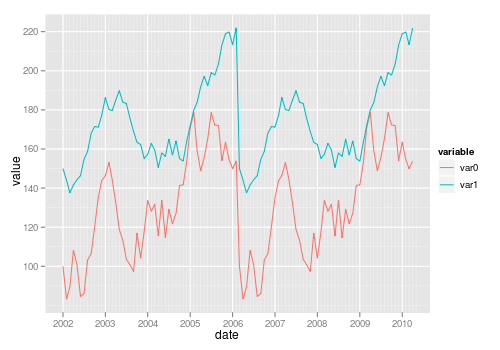
-
6Вы также можете использовать функцию
tidyrgather()пакетаtidyrдляtidyrданных:gather(test_data, variable, value, -date)
Вам нужно, чтобы данные были в "высоком" формате вместо "wide" для ggplot2. "широкий" означает наличие наблюдения за строку с каждой переменной в виде другого столбца (как и у вас сейчас). Вам нужно преобразовать его в "высокий" формат, где у вас есть столбец, который сообщает вам имя переменной и другой столбец, в котором указывается значение переменной. Процесс перехода от широкого к высокому обычно называют "плавлением". Вы можете использовать tidyr::gather для растапливания вашего фрейма данных:
library(ggplot2)
library(tidyr)
test_data <-
data.frame(
var0 = 100 + c(0, cumsum(runif(49, -20, 20))),
var1 = 150 + c(0, cumsum(runif(49, -10, 10))),
date = seq(as.Date("2002-01-01"), by="1 month", length.out=100)
)
test_data %>%
gather(key,value, var0, var1) %>%
ggplot(aes(x=date, y=value, colour=key)) +
geom_line()
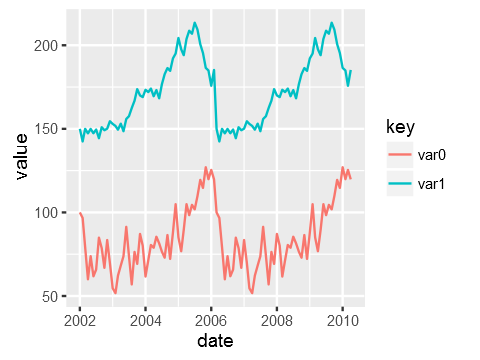
Просто чтобы очистить data, который ggplot потребляет после его прокладки через gather, выглядит следующим образом:
date key value
2002-01-01 var0 100.00000
2002-02-01 var0 115.16388
...
2007-11-01 var1 114.86302
2007-12-01 var1 119.30996
Использование ваших данных:
test_data <- data.frame(
var0 = 100 + c(0, cumsum(runif(49, -20, 20))),
var1 = 150 + c(0, cumsum(runif(49, -10, 10))),
Dates = seq.Date(as.Date("2002-01-01"), by="1 month", length.out=100))
Я создаю сложную версию, с которой ggplot() хотел бы работать с:
stacked <- with(test_data,
data.frame(value = c(var0, var1),
variable = factor(rep(c("Var0","Var1"),
each = NROW(test_data))),
Dates = rep(Dates, 2)))
В этом случае создание stacked было довольно простым, так как нам нужно было сделать пару манипуляций, но reshape() и reshape и reshape2 могут быть полезны, если у вас есть более сложные реальные данные, манипулировать.
После того, как данные находятся в этой сложной форме, для этого требуется только простой вызов ggplot() для создания сюжета, который вам нужен, со всеми дополнительными функциями (одна из причин, по которой пакеты построения более высокого уровня, такие как lattice и ggplot2, полезно):
require(ggplot2)
p <- ggplot(stacked, aes(Dates, value, colour = variable))
p + geom_line()
Я оставлю это вам, чтобы привести в порядок ярлыки оси, название легенды и т.д.
НТН
-
1Я думаю, что у вас есть неуместные парни в вашем коде там. Я думаю, что это то, что вы после: сложены <- с (test_data, data.frame (значение = c (var0, var1), переменная = фактор (rep (c ("Var0", "Var1"))), каждый = NROW (test_data), Dates = rep (date, 2))). Кроме того, какова цель столбца «каждый»? И разве это не просто более запутанный и менее эффективный способ расплавления данных, как показывает rcs? Я полагаю, я мог бы вообразить случай, когда melt не справился бы с работой, но это почти наверняка правильный инструмент для этой работы, если я что-то упустил?
-
1@ chase, извините, Emacs ESS неправильно делает отступы. каждый из них является аргументом для
rep(), поэтому мы получаем только 3 столбца вstacked. Я отредактирую код, чтобы сделать отступ более понятным.
Я также новичок в R, но, пытаясь понять, как работает ggplot, я думаю, у меня есть другой способ сделать это. Я просто поделюсь, вероятно, не как совершенное идеальное решение, а добавлю несколько разных точек зрения.
Я знаю, что ggplot лучше работает с фреймами данных, но иногда полезно знать, что вы можете напрямую построить два вектора без использования фрейма данных.
var0 <- 100 + c(0, cumsum(runif(49, -20, 20)))
var1 <- 150 + c(0, cumsum(runif(49, -10, 10)))
date <- seq(as.Date("2002-01-01"), by="1 month", length.out=50)
ggplot() + geom_line(aes(x=date,y=var0),color='red') + geom_line(aes(x=date,y=var1),color='blue') + ylab('Values')+xlab('date')
Длина вектора исходной даты равна 100, тогда как var0 и var1 имеют длину 50, поэтому я только отображаю доступные данные (первые 50 дат).
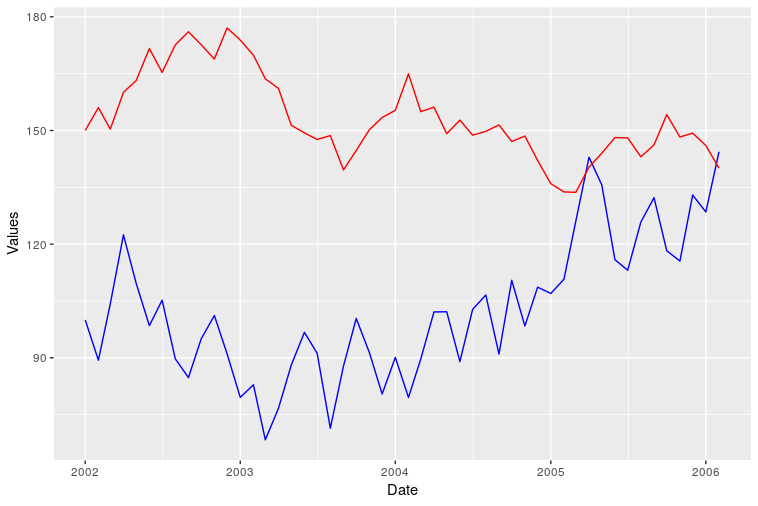
Однако я не смог добавить правильную легенду, используя этот формат. Кто-нибудь знает как?
Ещё вопросы
- 1Набор тегов API Google Tag Manager overrideGaSettings = false при создании тега
- 0AngularJS: вложенные директивы - передача данных не работает
- 0HTML / CSS ссылки на Facebook
- 0Переменная как ключ массива - выбрано выпадающее меню Yii
- 1Linq to sql Отличное после присоединения
- 1Tkinter: список флажков не отвечает
- 1Объединение массивов Numpy 2d при гарантированном ненулевом равенстве
- 1вызов метода рендеринга из другого класса
- 0проблемы с пустым полем
- 1RegExp для соответствия между двумя символами
- 0Как закрыть другой аккордеон в угловых js
- 1Заполните один столбец последнего элемента в группе значением другого столбца
- 1Что делает getExternalFilesDir (), если SD-карта не установлена?
- 1Как я могу выяснить и получить доступ к подклассам предупреждений панд?
- 0Открывать новую страницу, когда пользователь нажимает на любой элемент из ion-item
- 1Как разрешить исключение com.android.builder.dexing.DexArchiveBuilderException?
- 0Использование всплывающей подсказки jquery несколько раз на одной странице
- 1Как добавить строку в сценарии Java с предварительным увеличением в той же строке
- 1Изображение Android не вращается после 1-го запуска с помощью ViewPropertyAnimator
- 0libssh2_config.h не создается при установке libssh2
- 1Получение метаданных сущности с помощью веб-API
- 0содержание аккордеона не отображается - JQuery
- 1Почему я должен иметь двойные кавычки внутри одинарных кавычек в JavaScript?
- 0MySQL объединения данных назначить тот же идентификатор
- 0проверить числовое значение, используя .submit jquery
- 0Qt Сбой при двойном нажатии на элемент listWidget
- 0CSS / HTML для отображения строк вертикальной таблицы (или эквивалент)
- 0Нужен ли тип шифрования для подключения к внешней базе данных в Xamarin?
- 1Внедрение зависимостей только для базовой активности приводит к сбою дочерней активности
- 0Rails - Получить URL-адрес Paperclip с помощью SQL-запроса
- 0PHP imap - получать сообщения, полученные за последний час
- 1Цикл while для определения, является ли введенное значение двойным
- 1System.DayOfWeek enum - ошибки сущностей при сохранении с проблемами KnownType; DevForce 2012
- 1Сервис автоматического выхода из системы в приложении wpf
- 0Удаление замораживающей панели после сбоя проверки на клиенте с использованием jQuery
- 0как переписать URL в Yii?
- 0Кнопка для удаления записи в таблице
- 0Представления не обновляются после изменений - Play Framework 2
- 1чтение файла WAV в Java
- 1Touchable не работает с позицией: абсолют
- 1Интерполяция в пандах по горизонтали не зависит от каждой строки
- 1double.ToString («G»), но всегда включать точку?
- 1pandas.read_csv () интерпретирует TRUE как логическое значение, мне нужна строка
- 0Экспресс не получает данные от angularjs
- 0Фон раздела div имеет необъяснимые отступы. Почему?
- 1EF: Должен ли я включать идентификаторы внешнего ключа в мои объекты?
- 1Разница между развертыванием WAR и папки Build
- 0Обновление номера в подсказках jQuery UI
- 1Ошибка типа: объект 'module' не вызывается: модуль Calender
- 1Добавление слушателей в Amcharts с Angular4 [дубликаты]

colour=качестве имени переменной.