Разбор JSON с инструментами Unix
Я пытаюсь разобрать JSON, возвращенный из запроса curl, например:
curl 'http://twitter.com/users/username.json' |
sed -e 's/[{}]/''/g' |
awk -v k="text" '{n=split($0,a,","); for (i=1; i<=n; i++) print a[i]}'
Вышеуказанное разбивает JSON на поля, например:
% ...
"geo_enabled":false
"friends_count":245
"profile_text_color":"000000"
"status":"in_reply_to_screen_name":null
"source":"web"
"truncated":false
"text":"My status"
"favorited":false
% ...
Как напечатать определенное поле (обозначено -v k=text)?
-
4Эээ ... это не очень хороший анализ json, кстати ... как насчет escape-символов в строках ... и т.д. Есть ли на SO ответ на python (даже на perl ...)?martinr
-
1Ответ Python на это заключается в том, чтобы просто использовать библиотеку Python JSON, которая на самом деле будет анализировать JSON. sed и AWK предоставляют регулярные выражения, но они не являются хорошим решением проблемы правильного синтаксического анализа JSON.steveha
44 ответа
Существует несколько инструментов, специально предназначенных для управления JSON из командной строки, и будет намного проще и надежнее, чем делать с Awk, например jq:
curl -s 'https://api.github.com/users/lambda' | jq -r '.name'
Вы также можете сделать это с помощью инструментов, которые, вероятно, уже установлены в вашей системе, например Python, с помощью модуля json, и поэтому избегайте любых дополнительных зависимостей, при этом все еще пользуясь надлежащим парсером JSON. Далее предполагается, что вы хотите использовать UTF-8, который должен быть закодирован исходным JSON, и это то, что используют большинство современных терминалов:
Python 2:
export PYTHONIOENCODING=utf8
curl -s 'https://api.github.com/users/lambda' | \
python -c "import sys, json; print json.load(sys.stdin)['name']"
Python 3:
curl -s 'https://api.github.com/users/lambda' | \
python3 -c "import sys, json; print(json.load(sys.stdin)['name'])"
Исторические заметки
Этот ответ первоначально рекомендовал jsawk, который должен по-прежнему работать, но немного более громоздко использовать, чем jq, и зависит на установленном автономном интерпретаторе JavaScript, который менее распространен, чем интерпретатор Python, поэтому, вероятно, предпочтительные ответы:
curl -s 'https://api.github.com/users/lambda' | jsawk -a 'return this.name'
Этот ответ также первоначально использовал API Twitter из вопроса, но этот API больше не работает, что затрудняет копирование примеров для тестирования, а для нового API Twitter API требуются ключи API, поэтому я переключился на использование API GitHub, который можно легко использовать без ключей API. Первый ответ на исходный вопрос:
curl 'http://twitter.com/users/username.json' | jq -r '.text'
-
21Я не хотел добавлять зависимости в проект, поэтому я хочу использовать sed / awk / curl, но jsawk кажется наиболее «надежным» решением.
-
1Да, я понимаю, что не хочу добавлять дополнительные зависимости. Но JSON немного подходит для обычного
awkанализа, поэтому я подумал, что должен указать на то, что похоже на то, что было создано для того, что вы пытаетесь сделать.
Чтобы быстро извлечь значения для определенного ключа, мне лично нравится использовать "grep -o", который возвращает только соответствие регулярному выражению. Например, чтобы получить поле "текст" из твитов, например:
grep -Po '"text":.*?[^\\]",' tweets.json
Это регулярное выражение более надежное, чем вы думаете; например, он отлично разбирается со строками, имеющими встроенные запятые и скрытыми кавычками внутри них. Я думаю, что с немного дополнительной работой вы могли бы создать тот, который на самом деле гарантированно извлекает значение, если оно будет атомарным. (Если он имеет гнездование, то регулярное выражение не может этого сделать, конечно.)
И для дальнейшей очистки (хотя и сохранения оригинального экранирования строки) вы можете использовать что-то вроде: | perl -pe 's/"text"://; s/^"//; s/",$//'. (Я сделал это для этот анализ.)
Для всех ненавистников, которые настаивают на том, что вы должны использовать настоящий парсер JSON - да, это важно для правильности, но
- Чтобы сделать действительно быстрый анализ, например, подсчитывать значения, чтобы проверять ошибки очистки данных или получать общее представление о данных, быстрее удалять что-то из командной строки. Открытие редактора для записи script отвлекает.
-
grep -oна порядок быстрее, чем стандартная библиотекаjsonна Python, по крайней мере, когда вы делаете это для твитов (каждая составляет ~ 2 КБ). Я не уверен, что это просто потому, чтоjsonмедленный (я должен иногда сравнивать с yajl); но в принципе, регулярное выражение должно быть быстрее, поскольку оно является конечным состоянием и гораздо более оптимизированным, вместо парсера, который должен поддерживать рекурсию, и в этом случае тратит много деревьев на сборку зданий для структур, которые вам не нужны. (Если кто-то написал конечный преобразователь состояния, который сделал правильный (ограниченный глубиной) разбор JSON, это было бы фантастично! Тем временем у нас есть "grep -o".)
Чтобы написать поддерживаемый код, я всегда использую настоящую парсинговую библиотеку. Я не пробовал jsawk, но если он работает хорошо, это касается точки № 1.
Последнее, более wackier, решение: я написал script, который использует Python json и извлекает нужные вам ключи, в столбцы с разделителями столбцов; затем я прохожу через обертку вокруг awk, которая позволяет именованный доступ к столбцам. Здесь: скрипты json2tsv и tvvawk. Итак, для этого примера это будет:
json2tsv id text < tweets.json | tsvawk '{print "tweet " $id " is: " $text}'
Этот подход не относится к № 2, является более неэффективным, чем один Python script, и он немного хрупкий: он принудительно нормализует новые строки и вкладки в строковых значениях, чтобы играть хорошо с awk-полем/разделителем записей взгляд на мир. Но это позволяет вам оставаться в командной строке с большей точностью, чем grep -o.
-
0что если параметр last в кортеже thwn в конце не запятая, а правая скобка. И +1 точно.
-
0Привет Йола, верно, это зависит от ввода. Вы должны посмотреть на это в первую очередь.
На основании того, что некоторые из рекомендаций здесь (esp в комментариях) предложили использовать Python, я был разочарован, чтобы не найти пример.
Итак, здесь один лайнер, чтобы получить одно значение из некоторых данных JSON. Предполагается, что вы передаете данные в (откуда-то) и поэтому должны быть полезны в контексте сценариев.
echo '{"hostname":"test","domainname":"example.com"}' | python -c 'import json,sys;obj=json.load(sys.stdin);print obj[0]["hostname"]'
-
0Я улучшил этот ответ ниже, чтобы использовать функцию bash: curl 'some_api' | getJsonVal 'ключ'
-
0
pythonpy( github.com/russell91/pythonpy почти всегда является лучшей альтернативойpython -c, хотя его нужно устанавливать с помощью pip. простоpy --ji -x 'x[0]["hostname"]'json вpy --ji -x 'x[0]["hostname"]'. Если вы не хотите использовать встроенную поддержку json_input, вы все равно можете автоматически импортировать их какpy 'json.loads(sys.stdin)[0]["hostname"]'
Следуя указаниям MartinR и Boecko:
$ curl -s 'http://twitter.com/users/username.json' | python -mjson.tool
Это даст вам очень дружелюбный результат. Очень удобно:
$ curl -s 'http://twitter.com/users/username.json' | python -mjson.tool | grep my_key
-
35Как бы вы извлекли конкретный ключ, как спрашивает OP?
-
2Лучший ответ на данный момент imho, нет необходимости устанавливать что-либо еще в большинстве дистрибутивов, и вы можете
| grep field. Спасибо!
Вы можете просто загрузить jq двоичный файл для своей платформы и запустить (chmod +x jq):
$ curl 'https://twitter.com/users/username.json' | ./jq -r '.name'
Он извлекает атрибут "name" из объекта json.
jq homepage говорит, что это похоже на sed для данных JSON.
-
25Для
jq,jq- удивительный инструмент. -
2Согласовано. Я не могу сравнить с jsawk из принятого ответа, поскольку я не использовал его, но для локальных экспериментов (где установка инструмента приемлема) я настоятельно рекомендую jq. Вот немного более обширный пример, который берет каждый элемент массива и синтезирует новый объект JSON с выбранными данными:
curl -s https://api.example.com/jobs | jq '.jobs[] | {id, o: .owner.username, dateCreated, s: .status.state}'
Используйте поддержку Python JSON вместо использования awk!
Что-то вроде этого:
curl -s http://twitter.com/users/username.json | \
python -c "import json,sys;obj=json.load(sys.stdin);print obj['name'];"
-
4Извините за попытку придумать хороший ответ ...: Я буду стараться изо всех сил. Чтобы избавиться от партизанства, нужно больше, чем написать сценарий awk!
-
7Почему вы используете переменную obj в этом решении oneliner? Это бесполезно и не хранится вообще? Вы пишете меньше, используя
json.load(sys.stdin)['"key']"качестве примера, например:curl -sL httpbin.org/ip | python -c "import json,sys; print json.load(sys.stdin)['origin']".
Использование Node.js
Если система имеет node, можно использовать флаги -p print и -e evaulate script с JSON.parse, чтобы вытащить любое значение, которое необходимо.
Простой пример с использованием строки JSON { "foo": "bar" } и вытягивания значения "foo":
$ node -pe 'JSON.parse(process.argv[1]).foo' '{ "foo": "bar" }'
bar
Поскольку у нас есть доступ к cat и другим утилитам, мы можем использовать это для файлов:
$ node -pe 'JSON.parse(process.argv[1]).foo' "$(cat foobar.json)"
bar
Или любой другой формат, такой как URL-адрес, содержащий JSON:
$ node -pe 'JSON.parse(process.argv[1]).name' "$(curl -s https://api.github.com/users/trevorsenior)"
Trevor Senior
-
1Спасибо! но в моем случае это работает только с
node -p -e 'JSON.parse(process.argv[1]).foo' '{ "foo": "bar" }'-e flagnode -p -e 'JSON.parse(process.argv[1]).foo' '{ "foo": "bar" }' -
27Трубы!
curl -s https://api.github.com/users/trevorsenior | node -pe "JSON.parse(require('fs').readFileSync('/dev/stdin').toString()).name"
Вы спросили, как стрелять себе в ногу, и я здесь, чтобы предоставить боеприпасы:
curl -s 'http://twitter.com/users/username.json' | sed -e 's/[{}]/''/g' | awk -v RS=',"' -F: '/^text/ {print $2}'
Вы можете использовать tr -d '{}' вместо sed. Но оставляя их полностью, кажется, тоже имеет желаемый эффект.
Если вы хотите удалить внешние кавычки, проведите результат выше, используя sed 's/\(^"\|"$\)//g'
Я думаю, что другие услышали достаточную тревогу. Я буду стоять рядом с мобильным телефоном, чтобы вызвать скорую. Пожар при готовности.
-
9Таким образом, ложь безумия, прочитайте это: stackoverflow.com/questions/1732348/…
-
1Я прочитал все ответы, и этот работает отлично для меня без каких-либо дополнительных зависимостей. +1
Использование Bash с Python
Создайте функцию Bash в файле .bash_rc
function getJsonVal () {
python -c "import json,sys;sys.stdout.write(json.dumps(json.load(sys.stdin)$1))";
}
Тогда
$ curl 'http://twitter.com/users/username.json' | getJsonVal "['text']"
My status
$
Вот такая же функция, но с проверкой ошибок.
function getJsonVal() {
if [ \( $# -ne 1 \) -o \( -t 0 \) ]; then
cat <<EOF
Usage: getJsonVal 'key' < /tmp/
-- or --
cat /tmp/input | getJsonVal 'key'
EOF
return;
fi;
python -c "import json,sys;sys.stdout.write(json.dumps(json.load(sys.stdin)$1))";
}
Где $# -ne 1 обеспечивает как минимум 1 вход, и -t 0 убедитесь, что вы перенаправляетесь из канала.
Хорошая вещь об этой реализации заключается в том, что вы можете получить доступ к вложенным значениям json и получить json в ответ! =)
Пример:
$ echo '{"foo": {"bar": "baz", "a": [1,2,3]}}' | getJsonVal "['foo']['a'][1]"
2
Если вы хотите быть действительно причудливым, вы можете распечатать данные:
function getJsonVal () {
python -c "import json,sys;sys.stdout.write(json.dumps(json.load(sys.stdin)$1, sort_keys=True, indent=4))";
}
$ echo '{"foo": {"bar": "baz", "a": [1,2,3]}}' | getJsonVal "['foo']"
{
"a": [
1,
2,
3
],
"bar": "baz"
}
-
2+1 но вам действительно нужно избавиться от бесполезного использования
cat -
0Однострочник без функции bash:
curl http://foo | python -c 'import json,sys;obj=json.load(sys.stdin);print obj["environment"][0]["name"]'
$ curl 'https://api.github.com/repos/stedolan/jq/commits?per_page=5' | \
jq '.[0] | {message: .commit.message, name: .commit.committer.name}'
Разбор JSON с PHP CLI
Возможно, не в тему, но поскольку приоритет царит, этот вопрос остается неполным без упоминания нашего надежного и верного PHP, я прав?
Используя тот же пример JSON, но давайте присваиваем его переменной для уменьшения неопределенности.
$ export JSON='{"hostname":"test","domainname":"example.com"}'
Теперь для PHP goodness, используя file_get_contents и php://stdin.
$ echo $JSON|php -r 'echo json_decode(file_get_contents("php://stdin"))->hostname;'
или, как указано, используя fgets и уже открытый поток при постоянной константе CLI STDIN.
$ echo $JSON|php -r 'echo json_decode(fgets(STDIN))->hostname;'
NJoy!
-
0Я использую то же самое, что работает также с
fgets(STDIN) -
0Вы даже можете использовать
$argnвместоfgets(STDIN)
TickTick является парсером JSON, написанным в bash (< 250 строк кода)
Здесь авторский снипп из своей статьи Представьте мир, в котором bash поддерживает JSON:
#!/bin/bash
. ticktick.sh
``
people = {
"Writers": [
"Rod Serling",
"Charles Beaumont",
"Richard Matheson"
],
"Cast": {
"Rod Serling": { "Episodes": 156 },
"Martin Landau": { "Episodes": 2 },
"William Shatner": { "Episodes": 2 }
}
}
``
function printDirectors() {
echo " The ``people.Directors.length()`` Directors are:"
for director in ``people.Directors.items()``; do
printf " - %s\n" ${!director}
done
}
`` people.Directors = [ "John Brahm", "Douglas Heyes" ] ``
printDirectors
newDirector="Lamont Johnson"
`` people.Directors.push($newDirector) ``
printDirectors
echo "Shifted: "``people.Directors.shift()``
printDirectors
echo "Popped: "``people.Directors.pop()``
printDirectors
-
1Как единственный надежный ответ на этот вопрос, заслуживающий чистого внимания, это заслуживает большего числа голосов.
пожалуйста не делайте этого!
не используют линейно-ориентированные инструменты для анализа иерархических данных, сериализованных в текст. он работает только для особых случаев и будет преследовать вас и других людей. если вы действительно не можете использовать готовый json-парсер, напишите простой, используя рекурсивный спуск. это легко и будет выносить изменения, испускающая сторона справедливо рассматривает косметические (добавленные или удаленные пробелы, включая символы новой строки).
Нативная версия Bash: Также хорошо работает с обратными косыми чертами (\) и кавычками (")
function parse_json()
{
echo $1 | \
sed -e 's/[{}]/''/g' | \
sed -e 's/", "/'\",\"'/g' | \
sed -e 's/" ,"/'\",\"'/g' | \
sed -e 's/" , "/'\",\"'/g' | \
sed -e 's/","/'\"---SEPERATOR---\"'/g' | \
awk -F=':' -v RS='---SEPERATOR---' "\$1~/\"$2\"/ {print}" | \
sed -e "s/\"$2\"://" | \
tr -d "\n\t" | \
sed -e 's/\\"/"/g' | \
sed -e 's/\\\\/\\/g' | \
sed -e 's/^[ \t]*//g' | \
sed -e 's/^"//' -e 's/"$//'
}
parse_json '{"username":"john, doe","email":"[email protected]"}' username
parse_json '{"username":"john doe","email":"[email protected]"}' email
--- outputs ---
john, doe
[email protected]
-
0Это круто. Но если строка JSON содержит более одного ключа электронной почты, анализатор выдаст [email protected] "" [email protected]
-
0Не работает, если в письме есть тире вроде [email protected]
Не изобретайте колесо и не выбирайте из официального инструмента анализа JSON, рекомендованного создателем JSON: http://www.json.org/ (см. внизу)
Версия, которая использует Ruby и http://flori.github.com/json/
$ < file.json ruby -e "require 'rubygems'; require 'json'; puts JSON.pretty_generate(JSON[STDIN.read]);"
или более кратко:
$ < file.json ruby -r rubygems -r json -e "puts JSON.pretty_generate(JSON[STDIN.read]);"
-
3это мой любимый;) Кстати, вы можете сократить его с помощью ruby -rjson, чтобы потребовать библиотеку
-
0Обратите внимание, что финал
;не требуется в Ruby (он используется только для объединения операторов, которые обычно располагаются на отдельных строках в одну строку).
Кажется, что все недооценивают awk. Правда, одного или двух строк awk script не хватит. Но нетрудно написать настоящий JSON-парсер в awk. Я просто добавил один из своих awkenough.
Несколько лет спустя я предполагаю (извините), но я создал чистый bash script, который поддерживает вложенность и может легко получить значения.
Основная часть script:
curl "http://twitter.com/users/username.json" |
./JSON.sh |
grep -F -e "[\"text\"] |
cut -s -f 2 -d ' '
В рабочем каталоге script требуется JSON.sh.
Автор json-формата рекомендует использовать JSON.sh в bash (перейдите в www.json.org и прокрутите вниз до второго раздела и он указан в разделе "Bash" ).
Если вы хотите, чтобы ваш script находился только в одном файле .sh, вы можете скопировать и вставить команды throw, parse_array, parse_object, parse_value и parse в ваш script.
Измените script на следующее:
curl "http://twitter.com/users/username.json" |
grep -aoE '\"[^[:cntrl:]"\\]*((\\[^u[:cntrl:]]|\\u[0-9a-fA-F]{4})[^[:cntrl:]"\\]*)*\"|-?(0|[1-9][0-9]*)([.][0-9]*)?([eE][+-]?[0-9]*)?|null|false|true|[[:space:]]+$|.' --color=never |
grep -vE '^[[:space:]]+' |
parse |
grep -F -e "[\"text\"] |
cut -s -f 2 -d ' '
Как это работает:
-
curlполучает json файл, затем передает его наgrep. -
grep"tokenizes" json (он выводит строку, число или символ и т.д.), а затем передает ее на второйgrep, чья задача состоит в том, чтобы съесть пробелы. Это не относится к вам, если вы не копируете функции из JSON.sh. - Если вы копируете функции из JSON.sh, функция
parseрекурсивно выводит путь к значению, затем вкладку, а затем значение. Если вы этого не сделаете, то JSON.sh выполняет токенизацию, ест пустоты и вызывает внутреннюю функциюparse. Оба передают их вывод наgrep. -
grepищет список ключей и значений для пары, которую вы хотите. Он ищет ключ и выводит строку с ключом и значением. Как форматируются ключи: [aKey], гдеaKey- это ключ. Если ваш json вложен, он разделяется запятой. Если ваши значения находятся в массиве, используйте индекс массива (начиная с нуля), чтобы получить значение. Строка key/value переводится наcut(используйте несколько экземпляров -e "[aKey]", чтобы получить сразу несколько значений). -
cutразрезает строку по два с помощью вкладки в качестве разделителя, а затем печатает только значение.
Таким образом, вы можете использовать только файл script и использовать чистый bash и поддерживать вложенный json. Наслаждайтесь! (хотя теперь вы, вероятно, перешли к другим проектам).
Я создал модуль, специально предназначенный для манипуляции JSON с командной строкой:
https://github.com/ddopson/underscore-cli
- FLEXIBLE. Инструмент "swiss-army-knife" для обработки данных JSON - может использоваться как простой симпатичный принтер или как полноценная Javascript-команда.
- МОЩНЫЙ - предоставляет полную мощность и функциональность underscore.js(плюс underscore.string)
- ПРОСТОЙ - упрощает запись однострочных JS, аналогичных использованию "perl -pe"
- CHAINED. Несколько команд-команд можно связать вместе для создания конвейера обработки данных.
- MULTI-FORMAT. Богатая поддержка форматов ввода/вывода - довольно-печатная, строгая JSON, msgpack и т.д.
- DOCUMENTED - отличная документация по командной строке с несколькими примерами для каждой команды
Выбор поля довольно прост:
cat file.json | underscore extract field.subfield.subsubfield
По умолчанию он будет печатать вывод с "smart-whitespace", который является как читаемым, так и 100% строгим JSON (но вы можете выбрать другие форматы с флагами):
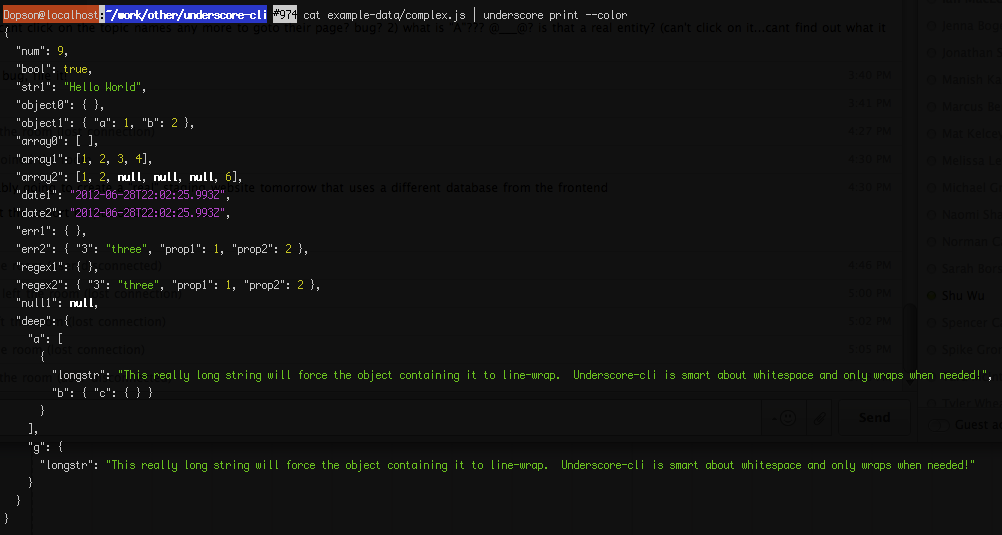
Если у вас есть какие-либо функции, прокомментируйте это сообщение или добавьте проблему в github. Я был бы рад определить приоритеты функций, которые необходимы членам сообщества.
К сожалению, верхний проголосовавший ответ, который использует grep, возвращает совпадение full, которое не работает в моем сценарии, но если вы знаете, что формат JSON останется постоянным, вы можете использовать lookbehind и lookahead для извлеките только нужные значения.
# echo '{"TotalPages":33,"FooBar":"he\"llo","anotherValue":100}' | grep -Po '(?<="FooBar":")(.*?)(?=",)'
he\"llo
# echo '{"TotalPages":33,"FooBar":"he\"llo","anotherValue":100}' | grep -Po '(?<="TotalPages":)(.*?)(?=,)'
33
# echo '{"TotalPages":33,"FooBar":"he\"llo","anotherValue":100}' | grep -Po '(?<="anotherValue":)(.*?)(?=})'
100
-
0Вы никогда не знаете порядок элементов в словаре JSON. Они по определению неупорядочены. Это как раз одна из фундаментальных причин, почему использование собственного JSON-парсера является обреченным подходом.
Вы можете использовать jshon:
curl 'http://twitter.com/users/username.json' | jshon -e text
-
0На сайте написано: «В два раза быстрее, 1/6 памяти», а затем: «Jshon анализирует, считывает и создает JSON. Он предназначен для максимально возможного использования из оболочки и заменяет хрупкие анализаторы adhoc, созданные из grep / sed / awk, а также тяжёлые однострочные парсеры из perl / python. "
-
0это указано в качестве рекомендуемого решения для анализа JSON в Bash
Если у вас php:
php -r 'var_export(json_decode(`curl http://twitter.com/users/username.json`, 1));'
Например:
У нас есть ресурс, который предоставляет json со странами iso-коды: http://country.io/iso3.json, и мы можем легко увидеть его в оболочке с curl:
curl http://country.io/iso3.json
но он выглядит не очень удобным и не читаемым, лучше разобрать json и увидеть читаемую структуру:
php -r 'var_export(json_decode(`curl http://country.io/iso3.json`, 1));'
Этот код напечатает что-то вроде:
array (
'BD' => 'BGD',
'BE' => 'BEL',
'BF' => 'BFA',
'BG' => 'BGR',
'BA' => 'BIH',
'BB' => 'BRB',
'WF' => 'WLF',
'BL' => 'BLM',
...
если у вас есть вложенные массивы, этот вывод будет выглядеть намного лучше...
Надеюсь, это поможет...
Для более сложного разбора JSON я предлагаю использовать модуль jsonpath python (by Stefan Goessner) -
- Установить его -
sudo easy_install -U jsonpath
- Используйте его -
Пример file.json(из http://goessner.net/articles/JsonPath) -
{ "store": {
"book": [
{ "category": "reference",
"author": "Nigel Rees",
"title": "Sayings of the Century",
"price": 8.95
},
{ "category": "fiction",
"author": "Evelyn Waugh",
"title": "Sword of Honour",
"price": 12.99
},
{ "category": "fiction",
"author": "Herman Melville",
"title": "Moby Dick",
"isbn": "0-553-21311-3",
"price": 8.99
},
{ "category": "fiction",
"author": "J. R. R. Tolkien",
"title": "The Lord of the Rings",
"isbn": "0-395-19395-8",
"price": 22.99
}
],
"bicycle": {
"color": "red",
"price": 19.95
}
}
}
Разберите его (извлеките все названия книг с ценой < 10) -
$ cat file.json | python -c "import sys, json, jsonpath; print '\n'.join(jsonpath.jsonpath(json.load(sys.stdin), 'store.book[?(@.price < 10)].title'))"
Выведет -
Sayings of the Century
Moby Dick
ПРИМЕЧАНИЕ. Вышеуказанная командная строка не включает проверку ошибок. для полного решения с проверкой ошибок вы должны создать небольшой python script и обернуть код с помощью try-except.
-
0красивая идиома. Я даже не знаю Python, но это кажется мощным решением
-
0У меня возникли небольшие проблемы с установкой
jsonpathпоэтому вместо этого был установленjsonpath_rw, поэтому вот что-то похожее, что вы можете попробовать, если вышеперечисленное не работает: 1)/usr/bin/python -m pip install jsonpath-rw2)cat ~/trash/file.json | /usr/bin/python -c "from jsonpath_rw import jsonpath, parse; import sys,json; jsonpath_expr = parse('store.book[0]'); out = [match.value for match in jsonpath_expr.find(json.load(sys.stdin))]; print out;"(Я использовал полный путь к двоичному файлу Python, потому что у меня были некоторые проблемы с несколькими установленными питонами).
Кому-то, у которого также есть xml файлы, может захотеть посмотреть на Xidel. Это беспроигрышный процессор JSONiq. (т.е. он также поддерживает XQuery для обработки xml или json)
Пример в вопросе:
xidel -e 'json("http://twitter.com/users/username.json")("name")'
Или с моим собственным, нестандартным синтаксисом расширения:
xidel -e 'json("http://twitter.com/users/username.json").name'
-
2Этот инструмент оооочень много больше, чем просто парсер JSON ...
-
0Или проще:
xidel -s https://api.github.com/users/lambda -e 'name'(или-e '$json/name', или-e '($json).name').
здесь один из способов сделать это с помощью awk
curl -sL 'http://twitter.com/users/username.json' | awk -F"," -v k="text" '{
gsub(/{|}/,"")
for(i=1;i<=NF;i++){
if ( $i ~ k ){
print $i
}
}
}'
Это может считаться оффтопическим, но это может быть полезно. Вот мой парсер JSON для URI Spotify:
wget -qO- "http://ws.spotify.com/lookup/1/.json?uri=[spotify url goes here]" | jsawk 'return this.track.artists[0].name + " - " + this.track.name + " (" + this.track.album.name + ")"'
script весьма полезен при использовании Spotify URI в качестве параметра (т.е. $1).
Если кто-то просто хочет извлечь значения из простых объектов JSON без необходимости вложенных структур, можно использовать регулярные выражения, даже не выходя из bash.
Вот функция, которую я определил с помощью регулярных выражений bash на основе стандарта JSON:
function json_extract() {
local key=$1
local json=$2
local string_regex='"([^"\]|\\.)*"'
local number_regex='-?(0|[1-9][0-9]*)(\.[0-9]+)?([eE][+-]?[0-9]+)?'
local value_regex="${string_regex}|${number_regex}|true|false|null"
local pair_regex="\"${key}\"[[:space:]]*:[[:space:]]*(${value_regex})"
if [[ ${json} =~ ${pair_regex} ]]; then
echo $(sed 's/^"\|"$//g' <<< "${BASH_REMATCH[1]}")
else
return 1
fi
}
Предостережения: объекты и массивы не поддерживаются как значение, но поддерживаются все другие типы значений, определенные в стандарте. Кроме того, пара будет сопоставляться независимо от того, насколько глубоко в документе JSON она сохраняется до тех пор, пока она имеет точно такое же ключевое имя.
Пример OP:
$ json_extract text "$(curl 'http://twitter.com/users/username.json')"
My status
$ json_extract friends_count "$(curl 'http://twitter.com/users/username.json')"
245
Это еще один гибридный ответ bash и python. Я опубликовал этот ответ, потому что мне хотелось обработать более сложный вывод JSON, но, уменьшив сложность моего приложения bash. Я хочу открыть следующий объект JSON из http://www.arcgis.com/sharing/rest/info?f=json в bash:
{
"owningSystemUrl": "http://www.arcgis.com",
"authInfo": {
"tokenServicesUrl": "https://www.arcgis.com/sharing/rest/generateToken",
"isTokenBasedSecurity": true
}
}
Хотя этот подход увеличивает сложность функции Python, использование bash становится проще:
function jsonGet {
python -c 'import json,sys
o=json.load(sys.stdin)
k="'$1'"
if k != "":
for a in k.split("."):
if isinstance(o, dict):
o=o[a] if a in o else ""
elif isinstance(o, list):
if a == "length":
o=str(len(o))
elif a == "join":
o=",".join(o)
else:
o=o[int(a)]
else:
o=""
if isinstance(o, str) or isinstance(o, unicode):
print o
else:
print json.dumps(o)
'
}
curl -s http://www.arcgis.com/sharing/rest/info?f=json | jsonGet
curl -s http://www.arcgis.com/sharing/rest/info?f=json | jsonGet authInfo
curl -s http://www.arcgis.com/sharing/rest/info?f=json | jsonGet authInfo.tokenServicesUrl
Выходной сигнал выше script:
- { "owningSystemUrl": " http://www.arcgis.com", "authInfo": { "tokenServicesUrl": " https://www.arcgis.com/sharing/rest/generateToken", "isTokenBasedSecurity": true}}
- { "tokenServicesUrl": " https://www.arcgis.com/sharing/rest/generateToken", "isTokenBasedSecurity": true}
- https://www.arcgis.com/sharing/rest/generateToken
Я добавил поддержку массивов, поэтому вы можете использовать .length, и если источник представляет собой строковый массив, вы можете использовать .join:
curl -s http://www.arcgis.com/sharing/rest/portals/self?f=pjson | jsonGet defaultBasemap.baseMapLayers.length
curl -s http://www.arcgis.com/sharing/rest/portals/self?f=pjson | jsonGet defaultBasemap.baseMapLayers.0.resourceInfo.tileInfo.lods
curl -s http://www.arcgis.com/sharing/rest/portals/self?f=pjson | jsonGet defaultBasemap.baseMapLayers.0.resourceInfo.tileInfo.lods.length
curl -s http://www.arcgis.com/sharing/rest/portals/self?f=pjson | jsonGet defaultBasemap.baseMapLayers.0.resourceInfo.tileInfo.lods.23
Какие выходы:
- 1
- [{ "scale" : 591657527.591555, "resolution" : 156543.03392800014, "level" : 0}, { "scale" : 295828763.795777, "resolution" : 78271.51696399994, "level" : 1}, { "scale" : 147914381.897889, "resolution" : 39135.75848200009, "level" : 2}, { "scale" : 73957190.948944, "resolution" : 19567.87924099992, "level" : 3}, { "scale" : 36978595.474472, "resolution" : 9783.93962049996, "level" : 4}, { "scale" : 18489297.737236, "resolution" : 4891.96981024998, "level" : 5}, { "scale" : 9244648.868618, "resolution" : 2445.98490512499, "level" : 6}, { "scale" : 4622324.434309, "разрешение" : 1222.992452562495, "level" : 7}, { "scale" : 2311162.217155, "resolution" : 611.4962262813797, "level" : 8}, { "scale" : 1155581.108577, "resolution" : 305.74811314055756, "level" : 9}, { "scale" : 577790.554289, "resolution" : 152.87405657041106, "level" : 10}, { "scale" : 288895.277144, "resolution" : 76.43702828507324, "level" : 11}, { "scale" : 144447.638572, "разрешение" : 38.21851414253662, "level" : 12}, { "scale" : 72223.819286, "resolution" : 19.109257071 26831, "level" : 13}, { "scale" : 36111.909643, "resolution" : 9.554628535634155, "level" : 14}, { "scale" : 18055.954822, "resolution" : 4.77731426794937, "level" : 15}, { "масштаб": 9027.977411, "разрешение" : 2.388657133974685, "уровень": 16}, { "масштаб": 4513.988705, "разрешение" : 1.1943285668550503, "уровень": 17}, { "шкала": 2256.994353, "разрешение" : 0,5971642835598172, "level" : 18}, { "scale" : 1128.497176, "resolution" : 0.29858214164761665, "level" : 19}, { "scale" : 564.248588, "resolution" : 0.14929107082380833, "level" : 20}, { "масштаб": 282.124294, "разрешение" : 0.07464553541190416, "уровень": 21}, { "шкала": 141.062147, "разрешение" : 0.03732276770595208, "уровень": 22}, { "масштаб": 70.5310735, "разрешение" : 0.01866138385297604, "level" : 23}]
- 24
- { "scale" : 70.5310735, "resolution" : 0.01866138385297604, "level" : 23}
Теперь, когда Powershell является кросс-платформой, я подумал, что я брошу туда путь, так как считаю, что это довольно интуитивно понятный и чрезвычайно простой.
curl -s 'https://api.github.com/users/lambda' | ConvertFrom-Json
ConvertFrom-Json преобразует JSON в пользовательский объект Powershell, поэтому вы можете легко работать со свойствами с этой точки вперед. Если вам нужно только свойство id, вы просто выполните следующее:
curl -s 'https://api.github.com/users/lambda' | ConvertFrom-Json | select -ExpandProperty id
Если вы хотите вызвать все это из Bash, тогда вам придется называть его следующим образом:
powershell 'curl -s "https://api.github.com/users/lambda" | ConvertFrom-Json'
Конечно, есть чистый способ Powershell сделать это без завитки, который был бы следующим:
Invoke-WebRequest 'https://api.github.com/users/lambda' | select -ExpandProperty Content | ConvertFrom-Json
Наконец, также есть "ConvertTo-Json", который так же легко преобразует пользовательский объект в JSON. Вот пример:
(New-Object PsObject -Property @{ Name = "Tester"; SomeList = @('one','two','three')}) | ConvertTo-Json
Что создало бы хороший JSON вот так:
{
"Name": "Tester",
"SomeList": [
"one",
"two",
"three"
]
}
По общему признанию, использование оболочки Windows в Unix несколько кощунственно, но Powershell действительно хорош в некоторых вещах, а парсинг JSON и XML - это пара из них. Это страница GitHub для кросс-платформенной версии https://github.com/PowerShell/PowerShell
-
0проголосовал за то, что вы продвигаете новую стратегию Microsoft по открытому исходному коду своих инструментов и включаете в себя иностранные инструменты с открытым исходным кодом. Это хорошо для нашего мира.
-
0Раньше мне не нравился PowerShell, но я должен признать, что обработка JSON очень хороша.
Если pip доступен в системе, то:
$ pip install json-query
Примеры использования:
$ curl -s http://0/file.json | json-query
{
"key":"value"
}
$ curl -s http://0/file.json | json-query my.key
value
$ curl -s http://0/file.json | json-query my.keys.
key_1
key_2
key_3
$ curl -s http://0/file.json | json-query my.keys.2
value_2
-
0Как найти json-массив длины использования пакета json-запроса?
Двухстрочный, который использует python. Он работает особенно хорошо, если вы пишете один файл .sh, и вы не хотите зависеть от другого .py файла. Он также использует использование трубы |. echo "{\"field\": \"value\"}" можно заменить чем-либо, печатающим json в stdout.
echo "{\"field\": \"value\"}" | python -c 'import sys, json
print(json.load(sys.stdin)["field"])'
-
0Вопрос не в поиске решения Python. Смотрите комментарии тоже.
Это хорошая утилита для pythonpy:
curl 'http://twitter.com/users/username.json' | py 'json.load(sys.stdin)["name"]'
-
0Еще короче, модуль Python -c здесь :) приятно.
Разбор JSON болезнен в оболочке script. С помощью более подходящего языка создайте инструмент, который извлекает атрибуты JSON в соответствии с соглашениями об использовании сценариев оболочки. Вы можете использовать свой новый инструмент для решения проблемы немедленного сценария оболочки, а затем добавить его в свой комплект для будущих ситуаций.
Например, рассмотрим инструмент jsonlookup таким образом, что если я скажу jsonlookup access token id, он вернет идентификатор атрибута, определенный в маркете атрибута, определенном в доступе атрибута от stdin, который, по-видимому, является данными JSON. Если атрибут не существует, инструмент ничего не возвращает (статус выхода 1). Если синтаксический анализ не выполняется, выйдите из состояния 2 и передайте сообщение stderr. Если поиск выполняется успешно, инструмент печатает значение атрибута.
Создав инструмент unix для точной цели извлечения значений JSON, вы можете легко использовать его в сценариях оболочки:
access_token=$(curl <some horrible crap> | jsonlookup access token id)
Любой язык будет использоваться для реализации jsonlookup. Вот довольно краткая версия python:
#!/usr/bin/python
import sys
import json
try: rep = json.loads(sys.stdin.read())
except:
sys.stderr.write(sys.argv[0] + ": unable to parse JSON from stdin\n")
sys.exit(2)
for key in sys.argv[1:]:
if key not in rep:
sys.exit(1)
rep = rep[key]
print rep
Вы можете попробовать что-то вроде этого -
curl -s 'http://twitter.com/users/jaypalsingh.json' |
awk -F=":" -v RS="," '$1~/"text"/ {print}'
Niet - это инструмент, который поможет вам извлекать данные из json или yaml файла непосредственно в CLI оболочки /bash.
$ pip install niet
Рассмотрим json файл с именем project.json со следующим содержимым:
{
project: {
meta: {
name: project-sample
}
}
Вы можете использовать niet следующим образом:
$ PROJECT_NAME=$(niet project.json project.meta.name)
$ echo ${PROJECT_NAME}
project-sample
Как насчет использования Rhino? Это инструмент командной строки JavaScript. К сожалению, это немного грубо для такого типа приложений. Он не читает из stdin очень хорошо.
Я использовал это, чтобы извлечь продолжительность видео с выхода ffprobe json:
MOVIE_INFO='ffprobe "path/to/movie.mp4" -show_streams -show_format -print_format json -v quiet'
MOVIE_SECONDS='echo "$MOVIE_INFO"|grep -w \"duration\" |tail -1 | cut -d\" -f4 |cut -d \. -f 1'
его можно использовать для извлечения значения из любого json:
value='echo "$jsondata"|grep -w \"key_name\" |tail -1 | cut -d\" -f4
-
1Если предполагается, что это допустимый сценарий оболочки, пробелы вокруг знака равенства в последнем фрагменте являются синтаксической ошибкой.
-
0@tripleee Исправлено. Tnx.
Вот хорошая ссылка. В этом случае:
curl 'http://twitter.com/users/username.json' | sed -e 's/[{}]/''/g' | awk -v k="text" '{n=split($0,a,","); for (i=1; i<=n; i++) { where = match(a[i], /\"text\"/); if(where) {print a[i]} } }'
-
0этот ответ должен получить наибольшее количество голосов, большинство, если не все остальные ответы зависят от пакета (php, python и т. д.).
-
0Нет, наоборот, ничто с бесполезным использованием
sedне должно получить больше голосов.
Я сделал это, "разобрав" ответ json для определенного значения следующим образом:
curl $url | grep $var | awk '{print $2}' | sed s/\"//g
Очевидно, что $url здесь будет URL-адресом twitter, а $var будет "text", чтобы получить ответ для этого var.
На самом деле, я думаю, что единственное, что я делаю в OP, оставил grep для строки с конкретной переменной, которую он ищет. Awk захватывает второй элемент на линии, и с sed я снимаю кавычки.
Кто-то умнее, чем я, возможно, мог бы сделать все это с помощью awk или grep.
Теперь вы можете сделать все это с помощью sed:
curl $url | sed '/text/!d' | sed s/\"text\"://g | sed s/\"//g | sed s/\ //g
Таким образом, нет awk, нет grep... Я не знаю, почему я об этом не думал раньше. Хммм...
-
0На самом деле, с Sed вы можете сделать
-
0
grep | awk | sedиsed | sed | sedТрубопроводыsed | sed | sed- это расточительные антипаттерны. Ваш последний пример может быть легко переписан вcurl "$url" | sed '/text/!d;s/\"text\"://g;s/\"//g;s/\ //g'но, как и другие отмечали, это и подвержено ошибкам, и хрупкое подход, который не следует рекомендовать в первую очередь.
Вы можете использовать bashJson
Это оболочка для модуля Python json и может обрабатывать сложные json-данные.
Давайте рассмотрим данные exlaple json из файла test.json
{
"name":"Test tool",
"author":"hack4mer",
"supported_os":{
"osx":{
"foo":"bar",
"min_version" : 10.12,
"tested_on" : [10.1,10.13]
},
"ubuntu":{
"min_version":14.04,
"tested_on" : 16.04
}
}
}
Следующие команды читают данные из этого примера json файла
/bashjson.sh test.json name
Печать: тестовый инструмент
./bashjson.sh test.json supported_os osx foo
Печать: бар
./bashjson.sh test.json supported_os osx tested_on
Печать: [10.1,10.13]
Существует также очень простой, но мощный инструмент обработки JSON CLI fx - https://github.com/antonmedv/fx

Примеры
Использовать анонимную функцию:
$ echo '{"key": "value"}' | fx "x => x.key"
value
Если вы не передадите анонимную функцию param =>..., код будет автоматически преобразован в анонимную функцию. И вы можете получить доступ к JSON по этому ключевому слову:
$ echo '[1,2,3]' | fx "this.map(x => x * 2)"
[2, 4, 6]
Или просто используйте точечный синтаксис:
$ echo '{"items": {"one": 1}}' | fx .items.one
1
Вы можете передать любое количество анонимных функций для уменьшения JSON:
$ echo '{"items": ["one", "two"]}' | fx "this.items" "this[1]"
two
Вы можете обновить существующий JSON с помощью оператора спредов:
$ echo '{"count": 0}' | fx "{...this, count: 1}"
{"count": 1}
Просто обычный JavaScript. Не нужно изучать новый синтаксис.
-
0Также статья: medv.io/json-in-bash
-
4Если вы продвигаете свое собственное творение, вы должны быть откровенными об этом. Смотрите, как не быть спамером.
Python может сделать это с помощью oneliner без дополнительных зависимостей:
например.
echo 'import urllib; import json; print json.load(urllib.urlopen( "http://api.wordpress.org/plugins/info/1.0/authenticator.json" )) [ "download_link" ] '| Python
уверен, что вы можете сделать его более читаемым:
echo '
import urllib
import json
print json.load(urllib.urlopen("http://api.wordpress.org/plugins/info/1.0/authenticator.json"))["download_link"]
' | python
jq определенно является хорошим выбором, как многие ответили выше. Я дам вам несколько быстрых советов, прежде чем отказаться от
Это выводит все поля в строке json:
jq keys YourJsonString
Это выдает поле, называемое "присоединением" всех ваших узлов:
jq '.files[].accession' YourJsonString
Обычно, если выходы следуют постоянному порядку, вы можете сопоставить поля, которые вам нужны, для создания таблицы, набрав это:
paste -s <(jq '.files[].href' YourJsonString) <(jq '.files[].accession' YourJsonString)
Существует более простой способ получить свойство из строки json. Используя пример файла package.json, попробуйте следующее:
#!/usr/bin/env bash
str=`cat package.json`;
my_val="$(node -pe "JSON.parse(\`$str\`)['version']")"
или
#!/usr/bin/env bash
prop="version"
my_val="$(node -pe "require('./package.json')['$prop']")"
оба метода работают отлично. наслаждаться.
читайте здесь: Прочитайте свойство name файла package.json с bash
-
0Использование конкатенации строк для подстановки значений в строку, анализируемую как код, позволяет запускать произвольный код node.js, что означает, что использовать его со случайным контентом, полученным из Интернета, крайне небезопасно. Есть причина, по которой безопасные / передовые методы анализа JSON в JavaScript не просто оценивают его.
Ещё вопросы
- 1Как это сделать, если вы не хотите читать всю строку?
- 0доступ к переменной соединения в цикле while
- 0Изменить размер Div динамически
- 0Angularjs сбрасывает радиовход, если щелкнуть два раза подряд
- 1Печать заявления только один раз в цикле
- 0Проверить ключ массива PHP> Значение
- 0Поддержка Knex для чтения реплик
- 1Клонировать массив с оператором распространения и добавить встроенный
- 1Панды, как добавить детали в CSV, прежде чем писать фрейм данных
- 1Сбой Android Lint для скриптов Gradle на основе Kotlin
- 0Вызов ActionResult из события OnChange [MVC4]
- 1Преобразование метки времени в дату ТОЛЬКО
- 0Еще один пример соединения с запросом mysql
- 0Как мне создать массив этой структуры в C ++ 11?
- 0событие backbutton (cordova) не влияет на переменные контроллера angularjs, как ожидалось
- 1Неожиданная ошибка при попытке объединить кадры данных с категориальными данными
- 0sql выбрать диапазон дат в следующем году
- 0Классы C ++. Значения внутри класса не обновляются
- 0Как эффективно вставить элементы в карту?
- 0Как обновить графику, чтобы избежать черного экрана?
- 0Подтвердите форму, но при отсутствии ошибок не показывайте поля
- 0Инициализация данных в пользовательскую модель из QAbstractTableModel в Qt?
- 0Мой конструктор копирования не удается .. как скопировать указатель на объект
- 1Почему я получаю AccessControlException: доступ запрещен при добавлении BouncyCastleProvider в сервлет Security in Tomcat
- 1Создание класса с помощью защищенного конструктора
- 0Угловые флажки не связываются должным образом
- 1Простой переводчик языка
- 0Выбрать и упорядочить список по другому условию (Критерии внутреннего объединения в спящий режим)
- 1Пытаясь создать код Python для печати электронной почты на веб-сайте с IMAP, localhost не отвечает
- 0Ошибка MySQL: 1251 не может добавить внешний ключ
- 0ссылки на хеш-теги javascript
- 0Вывести определенное значение массива после запроса в php yii2
- 1Javascript отображаемое имя div
- 1Как сохранить состояние экземпляра фрагмента после использования replace ()?
- 0запись имени файла - fwrite необходимо разделить символом «/»
- 0вектор emplace_back и shared_ptr в VS2012
- 0Как сохранить выбор флажка с тем же именем и идентификатором
- 1EditText - Cap слов без предложений?
- 0XPath YQL получать только определенные столбцы
- 0Двоичное дерево JavaScript с поиском по ширине
- 1(ASP.NET MVC4 C #) Вставьте UNICODE в SQL Server
- 0jQuery увеличение и уменьшение высоты div на основе позиционирования прокрутки
- 0Показать всех пользователей всех подразделений в активном каталоге, используя adLDAP?
- 1Расширения Chrome-Extensions Jasmine, Chrome, onMessage не определены
- 0Проблема с ионной прокруткой - прокрутка страницы прерывается при использовании ионной прокрутки
- 1Установка переменных среды в WinDbg
- 0Разложение LU в c ++ не работает на больших матрицах
- 1Управляемые событиями веб-приложения на Java?
- 0Даже после autoplay = «false» preload = «none», видео запускается без нажатия кнопки воспроизведения
- 1LinqToSql - SQL, сгенерированный CONCAT (UNION)
