Почему MATLAB так быстр в умножении матриц?
Я делаю некоторые тесты с CUDA, C++, С# и Java, и использую MATLAB для проверки и генерации матрицы. Но когда я умножаю с помощью MATLAB, матрицы 2048x2048 и даже больше умножаются практически мгновенно.
1024x1024 2048x2048 4096x4096
--------- --------- ---------
CUDA C (ms) 43.11 391.05 3407.99
C++ (ms) 6137.10 64369.29 551390.93
C# (ms) 10509.00 300684.00 2527250.00
Java (ms) 9149.90 92562.28 838357.94
MATLAB (ms) 75.01 423.10 3133.90
Только CUDA конкурентоспособна, но я думал, что по крайней мере C++ будет несколько ближе, а не в 60x медленнее.
Поэтому мой вопрос - как MATLAB делает это так быстро?
C++ Код:
float temp = 0;
timer.start();
for(int j = 0; j < rozmer; j++)
{
for (int k = 0; k < rozmer; k++)
{
temp = 0;
for (int m = 0; m < rozmer; m++)
{
temp = temp + matice1[j][m] * matice2[m][k];
}
matice3[j][k] = temp;
}
}
timer.stop();
Изменение: я также не знаю, что думать о результатах С#. Алгоритм такой же, как C++ и Java, но там гигантский скачок 2048 с 1024?
Edit2: обновлены результаты MATLAB и 4096x4096
-
13Вероятно, вопрос в том, какой алгоритм вы используете.Robert J.
-
24Убедитесь, что Matlab не кеширует ваш результат, это хитрый зверь. Сначала убедитесь, что расчет действительно выполняется, а затем сравните.rubenvb
15 ответов
Вот мои результаты с использованием MATLAB R2011a + Parallel Computing Toolbox на машине с Tesla C2070:
>> A = rand(1024); gA = gpuArray(A);
% warm up by executing the operations a couple of times, and then:
>> tic, C = A * A; toc
Elapsed time is 0.075396 seconds.
>> tic, gC = gA * gA; toc
Elapsed time is 0.008621 seconds.
MATLAB использует высоко оптимизированные библиотеки для умножения матриц, поэтому умножение матриц в обычном MATLAB такое быстрое. Версия gpuArray использует MAGMA.
Обновление с использованием R2014a на машине с Tesla K20c и новыми timeit и gputimeit:
>> A = rand(1024); gA = gpuArray(A);
>> timeit(@()A*A)
ans =
0.0324
>> gputimeit(@()gA*gA)
ans =
0.0022
Обновление с использованием R2018b на машине WIN64 с 16 физическими ядрами и Tesla V100:
>> timeit(@()A*A)
ans =
0.0229
>> gputimeit(@()gA*gA)
ans =
4.8019e-04
Этот вопрос повторяется и должен отвечать более четко, чем "Matlab использует высоко оптимизированные библиотеки" или "Matlab использует MKL" для Stackoverflow.
История:
Матричное умножение (вместе с матричным вектором, векторно-векторным умножением и многими матричными разложениями) является (являются) наиболее важными задачами линейной алгебры. Инженеры решали эти проблемы с компьютерами с первых дней.
Я не специалист по истории, но, видимо, тогда все просто переписали свою версию Fortran с помощью простых циклов. Затем появилась стандартизация с определением "ядер" (базовых процедур), которые необходимы для решения большинства задач линейной алгебры. Эти основные операции затем были стандартизованы в спецификации под названием "Основные подпрограммы линейной алгебры" (BLAS). Затем инженеры могли бы назвать эти стандартные, проверенные процедуры BLAS в своем коде, что значительно облегчит их работу.
BLAS:
BLAS эволюционировал от уровня 1 (первая версия, которая определяла операции вектор-вектор-вектор), до уровня 2 (векторно-матричные операции) до уровня 3 (матрично-матричные операции) и предоставляла все больше "ядер", поэтому стандартизировал все больше и больше фундаментальных операций линейной алгебры. Исходные версии Fortran 77 по-прежнему доступны на веб-сайте Netlib.
На пути к лучшей производительности:
Таким образом, за эти годы (в частности, между выпусками BLAS уровня 1 и уровня 2: начало 80-х) аппаратное обеспечение изменилось с появлением векторных операций и иерархии кэшей. Эти эволюции позволили существенно повысить производительность подпрограмм BLAS. Затем появились различные поставщики, которые выполняли процедуры BLAS, которые были более эффективными.
Я не знаю всех исторических реализаций (тогда я не родился и не был ребенком), но два из самых известных были выпущены в начале 2000-х: Intel MKL и GotoBLAS. Ваш Matlab использует Intel MKL, который является очень хорошим оптимизированным BLAS, и это объясняет большую производительность, которую вы видите.
Технические данные по умножению матрицы:
Итак, почему Matlab (MKL) так быстро работает в dgemm (двойное преобразование матричной матрицы с двойной точностью)? Простыми словами: потому что он использует векторизация и хорошее кэширование данных. В более сложных терминах: см. Статью , предоставленную Джонатаном Муром.
В основном, когда вы выполняете свое умножение в коде С++, который вы указали, вы совсем не используете кэш. Поскольку я подозреваю, что вы создали массив указателей на массивы строк, ваши обращения в вашем внутреннем цикле к k-му столбцу "matice2": matice2[m][k] очень медленные. Действительно, когда вы обращаетесь к matice2[0][k], вы должны получить k-й элемент массива 0 вашей матрицы. Затем на следующей итерации вы должны получить доступ к matice2[1][k], который является k-м элементом другого массива (массив 1). Затем в следующей итерации вы получаете доступ к еще одному массиву и т.д. Поскольку вся матрица matice2 не может вписываться в самые высокие кеши (она 8*1024*1024 байты большие), программа должна извлечь желаемый элемент из основного памяти, теряя много времени.
Если вы просто перенести матрицу, чтобы обращения были в смежных адресах памяти, ваш код уже выполнялся бы намного быстрее, потому что теперь компилятор может одновременно загружать целые строки в кеш. Просто попробуйте эту измененную версию:
timer.start();
float temp = 0;
//transpose matice2
for (int p = 0; p < rozmer; p++)
{
for (int q = 0; q < rozmer; q++)
{
tempmat[p][q] = matice2[q][p];
}
}
for(int j = 0; j < rozmer; j++)
{
for (int k = 0; k < rozmer; k++)
{
temp = 0;
for (int m = 0; m < rozmer; m++)
{
temp = temp + matice1[j][m] * tempmat[k][m];
}
matice3[j][k] = temp;
}
}
timer.stop();
Итак, вы можете видеть, как просто размер кеша значительно увеличил производительность вашего кода. Теперь реальные реализаторы dgemm используют это на очень обширном уровне: они выполняют умножение на блоки матрицы, определяемые размером TLB (буфер перевода с переводом, длинный рассказ: что можно эффективно кэшировать), чтобы потоки к процессору точно количество данных, которое он может обрабатывать. Другой аспект - векторизация, они используют векторизованные инструкции процессора для оптимальной пропускной способности команд, которые вы действительно не можете сделать из своего кросс-платформенного кода на С++.
Наконец, люди, утверждающие, что это из-за алгоритма Штрассена или Coppersmith-Winograd ошибочны, оба эти алгоритма не реализуются на практике из-за упомянутых выше технических соображений.
-
0Я только что посмотрел видео Скотта Мейерса о важности размеров кеша и подгонке данных к размерам строк кеша, а также о проблемах, которые могут возникнуть у многопоточных решений, у которых нет общих данных в источнике, но в итоге данные передаются на аппаратном уровне. / уровень основного потока: youtu.be/WDIkqP4JbkE
Вот почему. MATLAB не выполняет наивное матричное умножение, зацикливая на каждый отдельный элемент так, как вы делали в своем коде на С++.
Конечно, я предполагаю, что вы просто использовали C=A*B вместо написания функции умножения самостоятельно.
Matlab недавно включил LAPACK, поэтому я предполагаю, что их матричное умножение использует что-то, по крайней мере, так быстро. Исходный код LAPACK и документация легко доступны.
Вы также можете посмотреть на статью Goto и Van De Geijn "Анатомия высокопроизводительной матрицы" Умножение "на http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.140.1785&rep=rep1&type=pdf
-
6MATLAB использует библиотеку Intel MKL, которая обеспечивает оптимизированную реализацию подпрограмм BLAS / LAPACK: stackoverflow.com/a/16723946/97160
Ответ: библиотеки LAPACK и BLAS делают MATLAB ослепляюще быстрыми при работе с матрицами, а не проприетарным кодом для людей в MATLAB.
Используйте библиотеки LAPACK и/или BLAS в коде C++ для операций с матрицами, и вы должны получить такую же производительность, как MATLAB. Эти библиотеки должны быть свободно доступны в любой современной системе, и в академиях в течение десятилетий были разработаны части. Обратите внимание, что существует множество реализаций, включая некоторые закрытые источники, такие как Intel MKL.
Здесь доступно обсуждение того, как BLAS получает высокую производительность .
Кстати, это серьезная боль в моем опыте, чтобы вызвать библиотеки LAPACK непосредственно из c (но стоит). Вы должны прочитать документацию ОЧЕНЬ точно.
При умножении матрицы вы используете метод наивного умножения, который занимает время O(n^3).
Существует алгоритм умножения матрицы, который принимает O(n^2.4). Это означает, что при n=2000 ваш алгоритм требует в 100 раз больше вычислений, чем лучший алгоритм.
Вы должны действительно проверить страницу wikipedia для умножения матрицы для получения дополнительной информации об эффективных способах ее реализации.
-
0и MATLAB, вероятно, использует такой алгоритм, поскольку время умножения матрицы 1024 * 1024 меньше, чем время умножения матрицы 2048 * 2048 в 8 раз! Молодцы MATLAB, ребята.
-
3Я скорее сомневаюсь, что они используют «эффективные» алгоритмы умножения, несмотря на их теоретические преимущества. Даже у алгоритма Штрассена есть трудности с реализацией, а алгоритм Копперсмита-Винограда, о котором вы, вероятно, читали, просто не практичен (прямо сейчас). Кроме того, связанный поток SO: stackoverflow.com/questions/17716565/…
Вам нужно быть осторожным, чтобы делать честные сравнения с С++. Можете ли вы опубликовать код на С++, который показывает основные внутренние циклы, которые вы используете для умножения матриц? В основном, я беспокоюсь о вашем макете памяти и о том, что вы делаете это расточительно.
Я написал умножение матриц на С++, которое было так же быстро, как Matlab, но оно позаботилось. (EDIT: прежде чем Matlab использовал для этого графические процессоры.)
Вы можете практически гарантировать, что Matlab тратит очень мало циклов на эти "встроенные" функции. Мой вопрос: где вы тратите впустую циклы? (Без обид)
В зависимости от вашей версии Matlab, я считаю, что он может использовать ваш GPU уже.
Другое дело; Matlab отслеживает многие свойства вашей матрицы; ее диагональ, герметик и т.д., и специализируется на своих алгоритмах, основанных на этом. Может быть, его специализация основана на нулевой матрице, которую вы передаете, или что-то в этом роде? Может быть, это кеширование повторных вызовов функций, что испортило ваши тайминги? Возможно, он оптимизирует повторяющиеся неиспользуемые матричные продукты?
Чтобы избежать подобных ситуаций, используйте матрицу случайных чисел и убедитесь, что вы принудительно выполняете ее, распечатывая результат на экране или диске или что-то вроде этого.
-
4Как опытный пользователь ML, я могу сказать, что они еще не используют GPGPU. Новая версия matlab ДОЛЖНА использовать SSE1 / 2 (наконец). Но я сделал тесты. MexFunction, выполняющая поэлементное умножение, выполняется в два раза быстрее, чем
A.*BТак что ОП почти наверняка что-то обманывает. -
6Matlab с Parallel Computing Toolbox может использовать графический процессор CUDA, но это явно - вы должны отправить данные в графический процессор.
Используя два и один сплошной массив вместо трех отдельных, мой код С# почти с теми же результатами, что и С++/Java (с вашим кодом: 1024 - был немного быстрее, 2048 - около 140 и 4096) - было около 22 мин)
1024x1024 2048x2048 4096x4096
--------- --------- ---------
your C++ (ms) 6137.10 64369.29 551390.93
my C# (ms) 9730.00 90875.00 1062156.00
вот мой код:
const int rozmer = 1024;
double[][] matice1 = new double[rozmer * 3][];
Random rnd = new Random();
public Form1()
{
InitializeComponent();
System.Threading.Thread thr = new System.Threading.Thread(new System.Threading.ThreadStart(() =>
{
string res = "";
Stopwatch timer = new Stopwatch();
timer.Start();
double temp = 0;
int r2 = rozmer * 2;
for (int i = 0; i < rozmer*3; i++)
{
if (matice1[i] == null)
{
matice1[i] = new double[rozmer];
{
for (int e = 0; e < rozmer; e++)
{
matice1[i][e] = rnd.NextDouble();
}
}
}
}
timer.Stop();
res += timer.ElapsedMilliseconds.ToString();
int j = 0; int k = 0; int m = 0;
timer.Reset();
timer.Start();
for (j = 0; j < rozmer; j++)
{
for (k = 0; k < rozmer; k++)
{
temp = 0;
for (m = 0; m < rozmer; m++)
{
temp = temp + matice1[j][m] * matice1[m + rozmer][k];
}
matice1[j + r2][k] = temp;
}
}
timer.Stop();
this.Invoke((Action)delegate
{
this.Text = res + " : " + timer.ElapsedMilliseconds.ToString();
});
}));
thr.Start();
}
MATLAB использует высоко оптимизированную реализацию LAPACK от Intel, известную как Intel Math Kernel Library (Intel MKL) - в частности функция dgemm. Скорость. Эта библиотека использует преимущества функций процессора, включая инструкции SIMD и многоядерные процессоры. Они не документируют, какой конкретный алгоритм они используют. Если вы должны были позвонить Intel MKL из С++, вы должны увидеть аналогичную производительность.
Я не уверен, что библиотека MATLAB использует для умножения GPU, но, вероятно, что-то вроде nVidia CUBLAS.
-
1Вы правы, но видели ли вы этот ответ ? Тем не менее, IPP не является MKL, и MKL обладает гораздо более высокими характеристиками линейной алгебры по сравнению с IPP. Кроме того, IPP устарела в своих матричных математических модулях в последних версиях
-
0Извините, я имел в виду MKL не IPP
Потому что MATLAB - это язык программирования, изначально разработанный для числовой линейной алгебры (матричные манипуляции), в котором есть библиотеки, специально разработанные для умножения матриц. И теперь MATLAB также может использовать для этого графические процессоры (графические процессоры).
И если мы посмотрим на ваши результаты вычислений:
1024x1024 2048x2048 4096x4096 --------- --------- --------- CUDA C (ms) 43.11 391.05 3407.99 C++ (ms) 6137.10 64369.29 551390.93 C# (ms) 10509.00 300684.00 2527250.00 Java (ms) 9149.90 92562.28 838357.94 MATLAB (ms) 75.01 423.10 3133.90
тогда мы можем видеть, что не только MATLAB так быстр в умножении матриц: CUDA C (язык программирования от NVIDIA) дает лучшие результаты, чем MATLAB. CUDA C также имеет библиотеки, специально разработанные для умножения матриц, и использует графические процессоры.
Краткая история MATLAB
Клив Молер, председатель ветки информатики в Университете Нью-Мексико, начал разработку MATLAB в конце 1970-х годов. Он разработал его, чтобы предоставить своим студентам доступ к LINPACK (программная библиотека для выполнения числовой линейной алгебры) и EISPACK (программная библиотека для численного расчета линейной алгебры) без необходимости изучать Фортран. Вскоре он распространился на другие университеты и нашел сильную аудиторию в сообществе прикладной математики. Джек Литтл, инженер, подвергся воздействию этого факта во время визита Молера в Стэнфордский университет в 1983 году. Признавая его коммерческий потенциал, он присоединился к Молеру и Стиву Бангерту. Они переписали MATLAB на C и основали MathWorks в 1984 году, чтобы продолжить его развитие. Эти переписанные библиотеки были известны как JACKPAC. В 2000 году MATLAB был переписан для использования более нового набора библиотек для работы с матрицами, LAPACK (стандартная библиотека программного обеспечения для числовой линейной алгебры).
Что такое CUDA C
CUDA C также использует библиотеки, специально разработанные для умножения матриц, такие как OpenGL (Open Graphics Library). Он также использует GPU и Direct3D (в MS Windows).
Платформа CUDA предназначена для работы с такими языками программирования, как C, C++ и Fortran. Такая доступность облегчает специалистам по параллельному программированию использование ресурсов графического процессора, в отличие от предыдущих API, таких как Direct3D и OpenGL, которые требовали дополнительных навыков в графическом программировании. Кроме того, CUDA поддерживает фреймворки программирования, такие как OpenACC и OpenCL.
Пример потока обработки CUDA:
- Копировать данные из основной памяти в память графического процессора
- CPU запускает вычислительное ядро на GPU
- Ядра GPU CUDA выполняют ядро параллельно
- Скопируйте полученные данные из памяти графического процессора в основную память
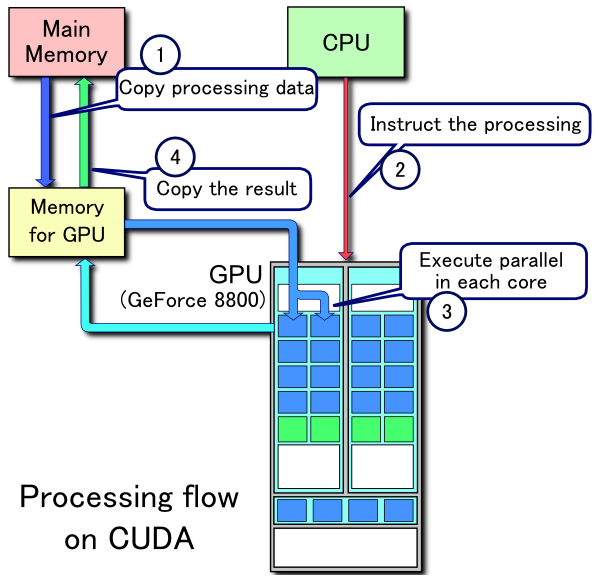
Сравнение скорости выполнения CPU и GPU
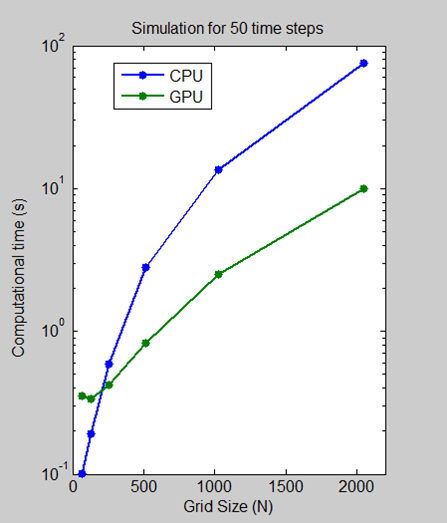
Мы выполнили тест, в котором мы измерили количество времени, которое потребовалось для выполнения 50 временных шагов для размеров сетки 64, 128, 512, 1024 и 2048 на процессоре Intel Xeon X5650, а затем с помощью графического процессора NVIDIA Tesla C2050.
Для размера сетки 2048 алгоритм показывает уменьшение времени вычислений в 7,5 раз с более минуты на ЦП до менее 10 секунд на ГП. График масштаба журнала показывает, что ЦП на самом деле быстрее для небольших размеров сетки. Однако по мере развития и развития технологии решения для графических процессоров все в большей степени способны справляться с небольшими проблемами, и мы ожидаем, что эта тенденция сохранится.
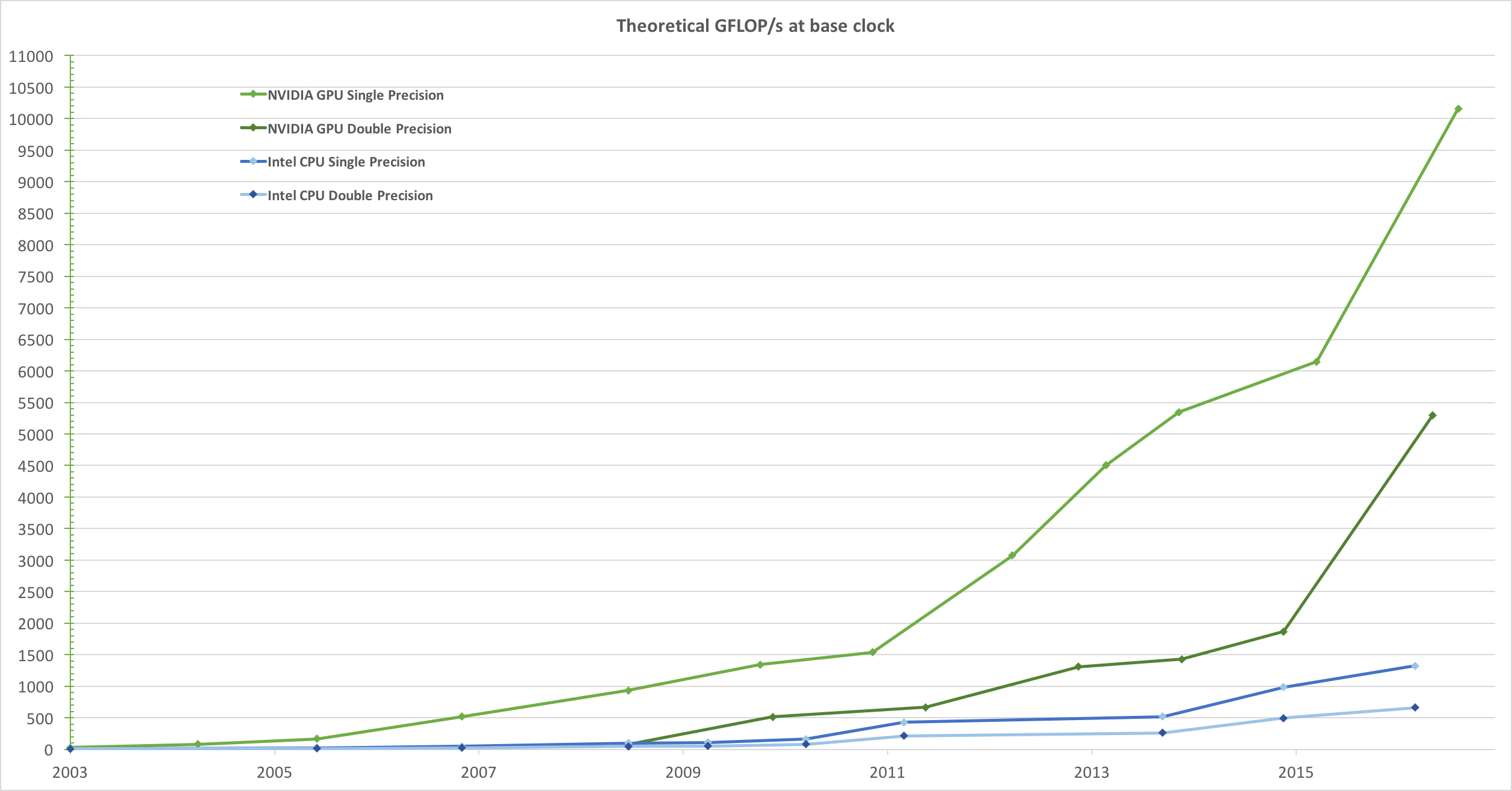
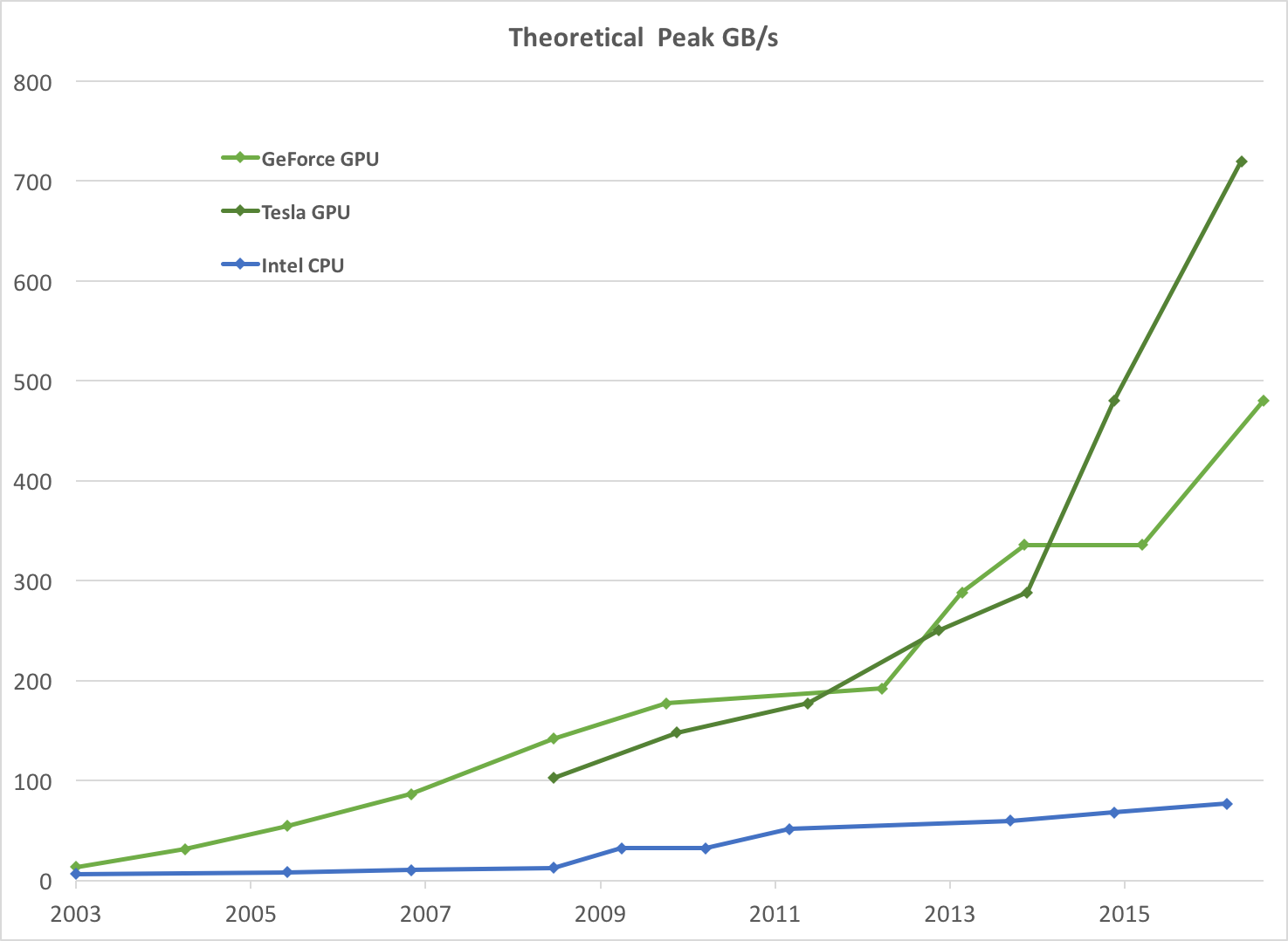
Из введения в Руководство по программированию CUDA C:
Вследствие ненасытного рыночного спроса на трехмерную графику высокой четкости в реальном времени программируемый графический процессор или графический процессор превратился в высокопараллельный многопоточный многоядерный процессор с огромной вычислительной мощностью и очень высокой пропускной способностью памяти, как показано на
Figure 1иFigure 2Рисунок 1. Операции с плавающей запятой в секунду для CPU и GPU
Рисунок 2 Пропускная способность памяти для процессора и графического процессора
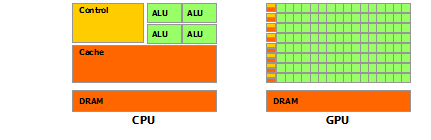
Причиной несоответствия в возможностях с плавающей запятой между процессором и графическим процессором является то, что графический процессор специализируется на вычислительных, высокопараллельных вычислениях - именно для этого предназначен рендеринг графики - и поэтому разработан таким образом, что большее количество транзисторов отводится обработке данных. а не кэширование данных и управление потоком, как схематически показано на
Figure 3.Рисунок 3 Графический процессор выделяет больше транзисторов для обработки данных
Более конкретно, графический процессор особенно хорошо подходит для решения проблем, которые могут быть выражены в виде параллельных вычислений данных - одна и та же программа выполняется на многих элементах данных параллельно - с высокой арифметической интенсивностью - отношение арифметических операций к операциям с памятью. Поскольку одна и та же программа выполняется для каждого элемента данных, существует более низкая потребность в сложном управлении потоком, а поскольку она выполняется для многих элементов данных и имеет высокую арифметическую интенсивность, задержка доступа к памяти может быть скрыта с помощью вычислений вместо больших кэшей данных.,
Параллельная обработка данных отображает элементы данных в потоки параллельной обработки. Многие приложения, которые обрабатывают большие наборы данных, могут использовать модель параллельного программирования для ускорения вычислений. При 3D-рендеринге большие наборы пикселей и вершин отображаются в параллельные потоки. Аналогично, приложения для обработки изображений и мультимедиа, такие как постобработка визуализированных изображений, кодирование и декодирование видео, масштабирование изображений, стереозрение и распознавание образов, могут отображать блоки изображений и пиксели в потоки параллельной обработки. Фактически, многие алгоритмы вне области рендеринга и обработки изображений ускоряются параллельной обработкой данных, от общей обработки сигналов или физического моделирования до вычислительных финансов или вычислительной биологии.
Расширенное чтение
- Графические процессоры (графический процессор)
- MATLAB
- Руководство по программированию CUDA C
- Использование графических процессоров в MATLAB
-
Анатомия высокопроизводительного матричного умножения, от Казушиге Гото и Роберта А. Ван Де Гейна
Некоторые интересные лица
Я написал C++ матричное умножение, такое же быстрое, как Matlab, но оно потребовало некоторой осторожности. (До этого Matlab использовал для этого графические процессоры).
Цитата из этого ответа.
-
0Эта последняя цитата не является «фактом», это пустое хвастовство. Этот человек получил несколько запросов на код, так как он опубликовал это. Но никакого кода не видно.
-
0Ваше описание того, как быстро вы можете выполнять вычисления на графическом процессоре, вообще не отвечает на этот вопрос. Все мы знаем, что 128 маленьких ядер могут выполнять больше одинаковой монотонной работы, чем два больших ядра. «И теперь MATLAB также может использовать для этого графические процессоры (графические процессоры)». Да, но не по умолчанию. Обычное матричное умножение все еще использует BLAS.
Он медленный в С++, потому что вы не используете многопоточность. По существу, если A = BC, где все они являются матрицами, первая строка A может быть вычислена независимо от 2-й строки и т.д. Если A, B и C - все n на n матриц, вы можете ускорить умножение на коэффициент n ^ 2, поскольку
a_ {i, j} = sum_ {k} b_ {i, k} c_ {k, j}
Если вы используете, скажем, Eigen [http://eigen.tuxfamily.org/dox/GettingStarted.html], многопоточность встроена и количество потоков регулируется.
Резкий контраст связан не только с оптимизацией Matlab (как уже обсуждалось многими другими ответами), но и с тем, как вы сформулировали матрицу как объект.
Кажется, вы сделали матрицу списком списков? Список списков содержит указатели на списки, которые затем содержат ваши матричные элементы. Расположение списков, содержащихся в списке, назначается произвольно. Когда вы перебираете свой первый индекс (номер строки?), Время доступа к памяти очень важно. Для сравнения, почему бы вам не попробовать реализовать матрицу как один список/вектор, используя следующий метод?
#include <vector>
struct matrix {
matrix(int x, int y) : n_row(x), n_col(y), M(x * y) {}
int n_row;
int n_col;
std::vector<double> M;
double &operator()(int i, int j);
};
И
double &matrix::operator()(int i, int j) {
return M[n_col * i + j];
}
Тот же алгоритм умножения должен использоваться так, чтобы число флопов было одинаковым. (n ^ 3 для квадратных матриц размера n)
Я прошу вас рассчитать время, чтобы результат был сопоставим с тем, что было раньше (на той же машине). При сравнении вы покажете, насколько важно значительное время доступа к памяти!
Общий ответ на вопрос "Почему Matlab быстрее выполняет xxx, чем другие программы", заключается в том, что в Matlab есть много встроенных оптимизированных функций.
Другие используемые программы часто не имеют этих функций, поэтому люди применяют свои собственные креативные решения, которые удивительно медленнее, чем профессионально оптимизированный код.
Это можно интерпретировать двумя способами:
1) Общий/теоретический способ: Matlab не значительно быстрее, вы просто ошибаетесь в производительности
2) Реалистично: для этого материала Matlab быстрее на практике, потому что языки как С++ просто слишком легко используются в неэффективных способах.
-
6Он сравнивает скорость MATLAB со скоростью функции, которую он написал за две минуты. Я могу написать более быструю функцию за 10 минут или намного более быструю функцию за два часа. Ребята из MATLAB потратили более двух часов на быстрое умножение матриц.
Вы проверили, что во всех реализациях используются многопоточные оптимизации для алгоритма? И использовали ли они один и тот же алгоритм умножения?
Я действительно сомневаюсь в этом.
Matlab не является неотъемлемо быстрым, вы, вероятно, использовали медленные реализации.
Ещё вопросы
- 1Каков лучший способ URL кодировать только ключи запроса и параметры в Java?
- 0Странная проблема со смещенной вершиной в jquery
- 0-webkit-transform проблемы с производительностью в Chrome
- 1React Native: событие onContentSizeChange для элемента TextInput не работает на Android
- 0Используйте mousedown и перетащите, чтобы увеличить изображения миниатюр?
- 0Параметры: где они объявлены?
- 0Тестирование углового модала открытое обещание
- 1Python: Работа с файлами XML не навязчиво
- 0Кнопка перекрытия с меткой
- 0кодировка символов для смешанных данных
- 1SelectionChanged показывает старое значение
- 0Object [object Object] не имеет метода
- 1Исключение, которое выдается, когда переменные экземпляра равны нулю
- 1Доступ к локали Struts2 в Spring AbstractRoutingDataSource
- 0как отобразить значение в div при нажатии кнопки?
- 0Как setlocale () работает в Windows?
- 1Colors.xml: содержимое не допускается в конце раздела
- 1Какой лучший способ сделать это вычисление панд?
- 0Как сделать родительский ли активным, когда ребенок меняется
- 1Запустите фоновый код, когда зарядное устройство подключится
- 0Как интегрировать Google Sparse Hash в C ++
- 0ngFlow - отправлять CSRF_token через угловой в laravel
- 0Проверка формы доступа извне
- 0Управление конфликтом событий в родительско-дочернем div
- 1Составление счета в Python 3
- 0Странное поведение Angular 1.3 при копировании элемента в NG-повтор
- 1Как сопоставить элементы JAXB в CIM / RDF?
- 0Получить HTML-теги как страницу из базы данных
- 1Плохо разработанное приложение: мы должны переписать?
- 0Риск запуска cronjob каждую минуту
- 1Что касается потоков в Swing GUI
- 0Как настроить вывод с помощью регулярного выражения в текстовой области
- 1Maven: неправильная версия Hibernate?
- 01066 - Не уникальный стол / псевдоним: «художники»
- 0Вызов хранимой процедуры / функции с помощью PHP в сегментированном кластере БД Mongo
- 0Как создать идентификатор родителя, а затем заставить ребенка ссылаться на него в многопоточной системе комментирования?
- 0Ошибка PHP в многопоточной среде, присваивающей значение родительскому статическому члену в том же потоке?
- 1Элемент [control_name] не является известным элементом. Это может произойти, если на веб-сайте произошла ошибка компиляции или отсутствует файл web.config
- 1Как получить значения translate3d?
- 0Избегание комментариев с C ++ getline ()
- 0Остановить автообновление
- 0Получить внешний HTML и затемнить / задержать полученные элементы
- 1figsize не влияет на рисунки в ноутбуке Jupyter
- 1Как установить имя файла при загрузке файла? [Дубликат]
- 1Добавьте вывод в раздел «СБОЙ» теста, не захватывая стандартный вывод
- 0Удалить escape-последовательности из разобранного HTML
- 1Проблема с D3.JS и Flask - попытка получить карту США
- 0использовать barcodeScanner в кордове (с angularjs)
- 3Как проверить пользовательскую функцию потерь в керасе?
- 0ngRepeat не работает в colorbox
