Что такое Scitime?
Scitime – это пакет Python, требующий по крайней мере Python 3.6 с зависимостями pandas, scikit-learn, psutil и joblib. Вы найдете репозиторий Scitime здесь.
Основная функция в этом пакете называется "Time". Учитывая матричный вектор X, предполагаемый вектор Y вместе с выбранной моделью Scikit Learn, time будет выводить как расчетное время, так и его доверительный интервал. Пакет в настоящее время поддерживает следующие алгоритмы Scikit Learn с планами добавить больше в ближайшем будущем:
- KMeans;
- RandomForestRegressor;
- SVC;
- RandomForestClassifier.
Быстрый старт
Давайте установим пакет и запустим основы.
Сначала создайте новый virtualenv (это необязательно, но в будущем позволит избежать конфликта версий!):

а затем запустить:

или с conda:
Как только установка прошла успешно, вы готовы оценить время вашего первого алгоритма.
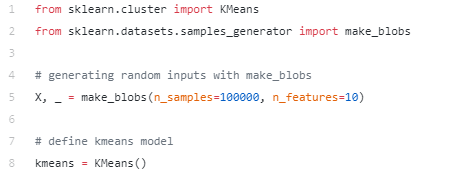
Допустим, вы хотели обучить кластеризацию kmeans. Сначала вам нужно будет импортировать пакет scikit-learn, установить параметры kmeans, а также выбрать входные данные (X), которые здесь сгенерированы случайным образом для простоты.
Выполнение этого перед выполнением фактической подгонки даст приблизительную оценку времени выполнения:
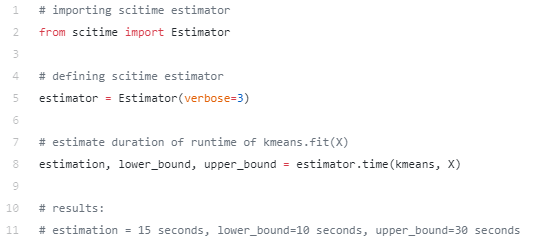
Как видите, вы можете получить эту информацию при помощи всего одной дополнительной строки кода! Входные данные функции времени – это именно то, что нужно для выполнения подгонки (то есть самого алгоритма и X), что делает его еще проще в использовании.
При более внимательном рассмотрении последней строки приведенного выше кода первый вывод (в данном случае оценка: 15 секунд) – это прогнозируемое время выполнения, которое вы ищете. Scitime также выведет его с доверительным интервалом (lower_bound и upper_bound: в данном случае 10 и 30 секунд). Вы всегда можете сравнить его с фактическим временем тренировочного времени, запустив:

В этом случае на нашей локальной машине оценка составляет 15 секунд, тогда как фактическое время обучения составляет 20 секунд (но вы можете получить другие результаты).
Краткое руководство
Класс оценки (meta_algo, verbose, confidence) класс:
- meta_algo: оценщик, используемый для прогнозирования времени: "RF" или "NN" (подробности см. в следующем абзаце) – по умолчанию "RF";
- verbose: контроль количества выходных данных журнала (0, 1, 2 или 3) – по умолчанию 0;
- confidence: Достоверность интервалов - по умолчанию 95%.
Функция estimator.time (algo, X, y):
- algo: algo, время выполнения которого пользователь хочет предсказать;
- X: бесчисленное множество входных данных для обучения;
- y: бесчисленное множество выходных данных, которые нужно обучить (установите None, если алгоритм не контролируется).
Небольшое замечание: чтобы избежать путаницы, стоит подчеркнуть, что algo и meta_algo здесь две разные вещи: algo – это алгоритм, время выполнения которого мы хотим оценить, meta_algo – это алгоритм, используемый Scitime для прогнозирования времени выполнения.
Как работает Scitime
Мы можем предсказать время выполнения для согласования, используя наш собственный оценщик, который имеет название мета-алгоритмом (meta_algo), вес которого сохраняется в специальном файле pickle в метаданных пакета. Для каждой модели Scikit Learn вы найдете соответствующий файл мета-алгоритма в базе кода Scitime.
Вы можете подумать: "Почему бы вручную не оценить сложность времени с помощью больших обозначений O?".
Это справедливое замечание. Одна загвоздка, однако, состоит в том, что нам нужно было бы сформулировать явную сложность для каждого алгоритма и набора параметров, что довольно сложно в некоторых случаях, учитывая количество факторов, играющих роль во время выполнения. Meta_algo в основном делает всю работу за вас, и я объясню как.
Для оценки подходящего времени были обучены два типа мета-алгоритмов (оба из Scikit Learn):
- Мета-алгоритм RF, оценщик RandomForestRegressor.
- NN meta algo, базовый оценщик MLPRegressor.
Эти мета-алгоритмы оценивают время подгонки, используя массив "мета-функций". Вот краткое изложение того, как нужно строить эти функции:
Во-первых, мы выбираем форму вашей входной матрицы X и выходного вектора y. Во-вторых, учитываются параметры, которые вы вводите в модель Scikit Learn, поскольку они также влияют на время обучения. Наконец, также учитывается ваше конкретное оборудование, уникальное для вашей машины, такое как доступная память и количество процессоров.
Как было показано ранее, мы также предоставляем доверительные интервалы для прогнозирования времени. Способ их вычисления зависит от выбранного мета-алгоритма:
- Для RF, поскольку любой случайный лесной регрессор является комбинацией нескольких деревьев (также называемых оценщиками), доверительный интервал будет основан на распределении набора предсказаний, вычисленных каждым оценщиком;
- Для NN процесс немного сложнее: сначала мы вычисляем набор MSE вместе с количеством наблюдений на тестовом наборе, сгруппированных по прогнозным интервалам длительности (то есть от 0 до 1 секунды, от 1 до 5 секунд и т. д.), а затем мы вычисляем t-stat, чтобы получить нижнюю и верхнюю границы оценки. Поскольку у нас очень мало данных для очень длинных моделей, доверительный интервал для таких данных может стать очень широким.
Насколько точен Scitime?
Ниже мы подчеркиваем, как наши прогнозы выполняются для конкретного случая k средних. Наш сгенерированный набор данных содержит ~ 100 тыс. точек данных, которые мы разделили на цепочку и тестовые наборы (75% - 25%).
Мы сгруппировали прогнозируемое время обучения по разным временным интервалам и вычислили MAPE и RMSE по каждому из этих интервалов для всех наших оценщиков, используя мета-алгоритм RF и мета-алгоритм NN.
Обратите внимание, что эти результаты были выполнены для ограниченного набора данных, поэтому они могут отличаться в неизведанных точках данных (таких как другие системы/экстремальные значения некоторых параметров модели). Для этого конкретного тренировочного набора R-квадрат составляет около 80% для NN и 90% для RF.
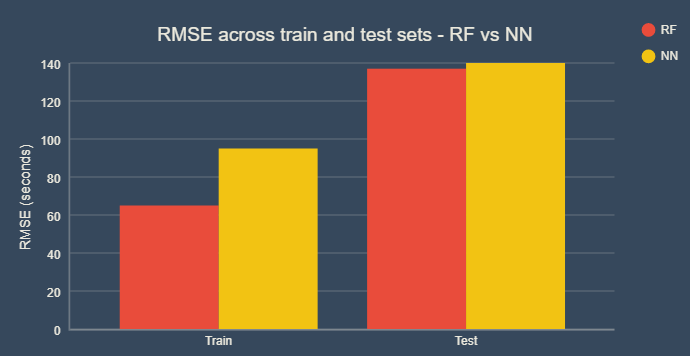
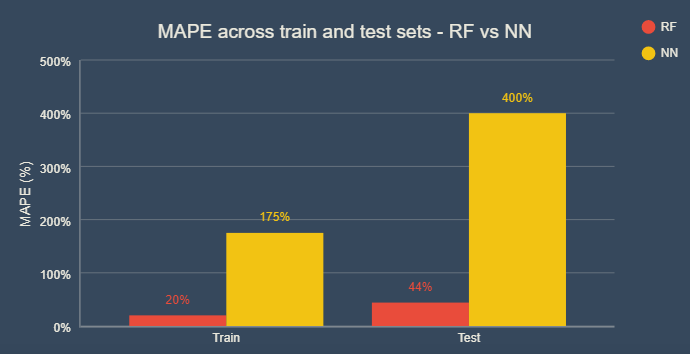
Как мы видим, неудивительно, что точность в наборе цепочек неизменно выше, чем в тесте, как для NN, так и для RF. Мы также видим, что RF работает лучше, чем NN в целом. MAPE для RF составляет около 20% в наборе цепочек и 40% в тестовом наборе. NN MAPE на удивление показывает высокие результаты.
Давайте нарежем MAPE (на тестовом наборе) на количество предсказанных секунд:
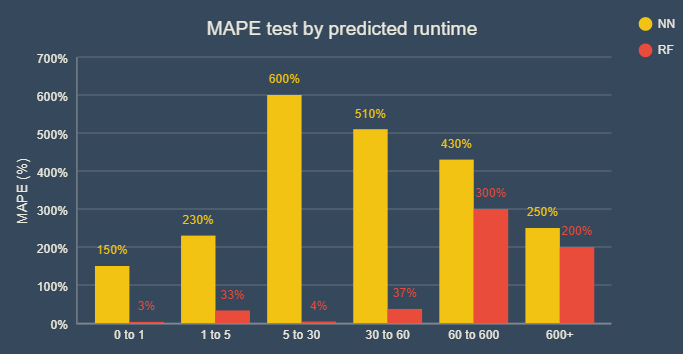
Важно помнить, что в некоторых случаях прогнозирование времени чувствительно к выбранному мета-алгоритму (RF или NN). По нашему опыту, RF очень хорошо работал в диапазонах ввода набора данных, как показано выше. Тем не менее, для точек вне диапазона, NN может работать лучше, как показано в конце приведенного выше графика. Это объясняет, почему NN MAPE достаточно высока, а RMSE – нормальная: она плохо работает при небольших значениях.
Ограничения
Как упоминалось ранее, первое ограничение связано с доверительными интервалами: они могут быть очень широкими, особенно для NN, и для тяжелых моделей (это может занять не менее часа).
Кроме того, NN может работать плохо при малых и средних прогнозах. Иногда для небольших длительностей NN может даже прогнозировать отрицательную длительность, и в этом случае мы автоматически переключаемся обратно на RF.
Еще одно ограничение оценки возникает, когда используются "специальные" значения параметров алгоритма. Например, в сценарии RandomForest, когда max_depth имеет значение None, глубина может принимать любое значение. Это может привести к гораздо более длительному времени для подгонки, что сложнее для мета-алгоритма, хотя мы сделали все возможное, чтобы их учесть.
При запуске estimator.time (algo, X, y) мы требуем, чтобы пользователь ввел фактический вектор X и y, который кажется ненужным, поскольку мы могли бы просто запросить форму данных для оценки времени обучения. Причина этого в том, что мы на самом деле пытаемся подобрать модель перед прогнозированием времени выполнения, чтобы вызвать любые мгновенные ошибки. Мы запускаем algo.fit (X, y) в подпроцессе на одну секунду, чтобы проверить наличие ошибок соответствия, после чего мы переходим к части прогнозирования. Однако бывают случаи, когда алгоритм (и/или матрица ввода) настолько велик, что запуск algo.fit (X, y) в конечном итоге приведет к ошибке памяти, которую мы не можем объяснить.